Data Consistency — Why It Becomes the Hardest Problem in Micro Services
1. The Moment Consistency Stops Being Guaranteed
Up to this point in the series, the shift from monolith to microservices has already changed how the system behaves under load and failure. But there is one area where the change is deeper than it first appears – that area is data.
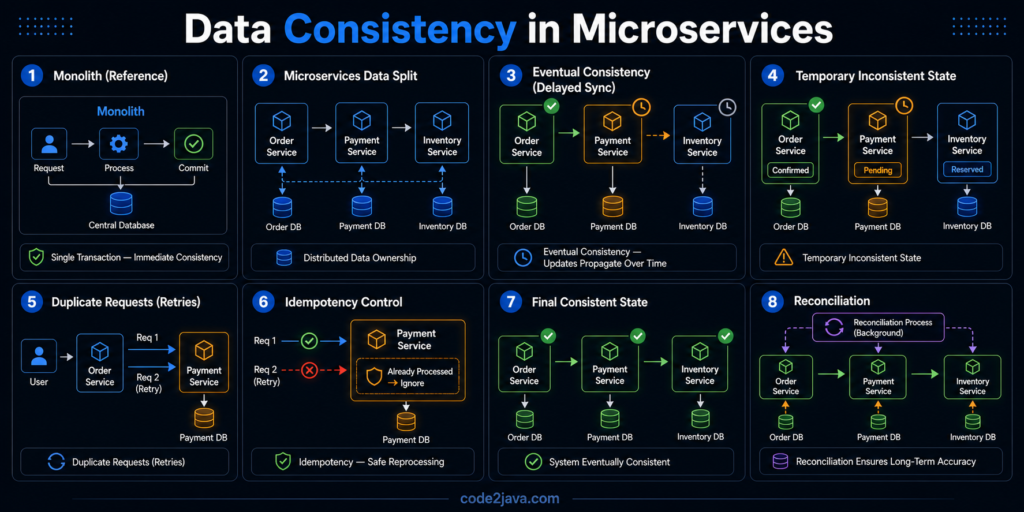
In a monolith, consistency is something you rarely think about explicitly. It is handled by the database – Transactions ensure that changes either happen completely or not at all. Once a transaction is committed, every part of the system sees the same state. This creates a very strong mental model, there is one source of truth, and it is always correct.
When you move to microservices, this model quietly breaks. There is ideally no single database anymore, each service owns its own data, each one updates its state independently. There is no shared transaction boundary that ties them together. At that point –
consistency is no longer guaranteed by the system – it becomes something you have to design.
2. Why a Single Source of Truth No Longer Exists
In a distributed system, data is intentionally split across services. Order Service stores orders – Payment Service stores transactions – Inventory Service stores stock levels. Each service is responsible for its own data and does not directly control others.
This separation is necessary for independence and scalability, but it introduces a new challenge. There is no single place where the complete state exists in real time.
If you want to understand the full picture of a request, you have to look across multiple services. And those services may not be perfectly in sync at any given moment.
For a short period of time, different parts of the system may have different versions of the truth, this is not a failure – it is a natural outcome of distribution.
3. Understanding Eventual Consistency in Practice
To deal with this, distributed systems rely on a concept called eventual consistency. Instead of guaranteeing that all services are consistent at the same moment, the system guarantees that they will become consistent over time.
When one service updates its data, it communicates that change to others, often through events or messages. Those services process the update when they receive it. This introduces a delay between when something happens and when every part of the system reflects that change. For example, an order may be created immediately, but inventory updates and notifications may happen slightly later. During that window, the system is temporarily inconsistent.
The important shift here is not technical—it is conceptual.
You move from expecting immediate correctness everywhere to accepting that correctness emerges over time.
4. When Delays Become Real Problems
While eventual consistency works in theory, it introduces challenges in real systems, the delay between updates can create confusion if not handled properly.
A user might see an order confirmed, but inventory might still show old data. A payment might be processed, but the order status may not yet reflect it. If the system is not designed carefully, these temporary inconsistencies can lead to incorrect decisions or poor user experience.
The problem is not that data is wrong, it is that different parts of the system are seeing it at different stages. This requires designing flows that can tolerate and correctly handle these intermediate states.
5. The Hidden Risk: Duplicate Operations
As soon as communication between services becomes asynchronous, another issue appears –
- Messages may be delivered more than once
- Requests may be retried
- Network failures may cause uncertainty about whether an operation completed.
This means the same action can be executed multiple times.
For example, a payment request might be processed twice if the system retries after a timeout but the original request was actually successful. This is not a rare edge case, it is a normal behaviour in distributed systems.
Handling this requires designing operations in a way that repeating them does not change the final outcome.
6. Why Idempotency Becomes Critical
This is where idempotency becomes essential. An idempotent operation is one that produces the same result no matter how many times it is executed.
In distributed systems, Idempotency is not just a good practice—it is a requirement.
If a payment request is received multiple times, the system must recognize that it has already been processed and avoid applying it again. This usually requires maintaining identifiers for operations and checking whether they have already been handled.
Without idempotency, the system cannot guarantee correctness in the presence of retries and duplicates.
7. Data Consistency Is Now a Flow, Not a State
One of the biggest mindset changes in microservices is how you think about data.
In a monolith, data is a state. You query it, and you get the current truth.
In microservices, data is a flow. Information moves from one service to another over time. The system’s overall state is the result of multiple updates happening across different services.
Understanding the system means understanding how data flows, not just where it is stored.
This is why designing events, message handling, and update sequences becomes as important as designing the data model itself.
8. Reconciling the System Over Time
Even with careful design, inconsistencies can still happen. Messages can be delayed. Services can fail temporarily. Updates may not propagate immediately.
To handle this, many systems introduce reconciliation processes. These are background mechanisms that periodically check for inconsistencies and correct them. For example, the system might verify that all completed payments have corresponding orders, or that inventory levels match expected values.
This is not a workaround, it is part of how distributed systems maintain long-term correctness.
Consistency is not enforced in a single step, it is maintained over time.
9. From Production Perspective
From a production perspective, data consistency is where most real-world issues appear, not because the system is broken, but because it behaves differently than expected.
Teams often assume that once an operation is completed, the entire system reflects that change immediately. In distributed systems, that assumption no longer holds. The first signs of issues are usually subtle:
- Temporary mismatches in data
- Duplicate processing of requests
- Delayed updates across services
These issues become visible under load, retries, or partial failures.
Stabilizing the system requires:
- Designing idempotent operations
- Handling delayed updates gracefully
- Introducing reconciliation where necessary
Over time, the system becomes reliable not because it avoids inconsistency, but because it manages it effectively.
Summary
Data consistency in microservices is fundamentally different from monoliths.
You move from:
- immediate consistency to eventual consistency
- a single source of truth to distributed data ownership
- guaranteed transactions to managed workflows
Consistency is no longer automatic. It is designed through:
- controlled data flow
- idempotent operations
- delayed synchronization
- reconciliation processes
Understanding this shift is critical, because in distributed systems, correctness is not something you get for free, it is something you build, maintain, and continuously verify.