Performance & Scalability — What Actually Happens at Runtime
1. Why Performance Feels Different in Microservices
By the time a system moves to microservices, there is usually an expectation that performance will improve naturally. The logic behind this assumption is straightforward, smaller services should execute faster, scaling should be more flexible, and load should distribute more evenly.
In practice, performance does not improve automatically. It changes in nature. What was once a single, predictable execution path inside one system becomes a sequence of interactions across multiple services. The system no longer behaves like a single application. It behaves like a network of independent components.
This shift changes how performance must be understood. Instead of optimizing one system, you now have to understand how multiple systems interact under load.
2. The Shift from CPU Time to Network Time
In a monolith, most of the time spent processing a request is consumed by computation and database operations. Everything happens within the same memory space, and communication between components is immediate.
In microservices, communication moves to the network, every interaction between services requires data to be serialized, transmitted, and reconstructed. This introduces additional overhead that did not exist before.
More importantly, network behaviour is not stable. Latency varies based on load, congestion, retries, and failures. As a result, execution time becomes less predictable. What used to be a relatively stable operation now carries variability at every step.
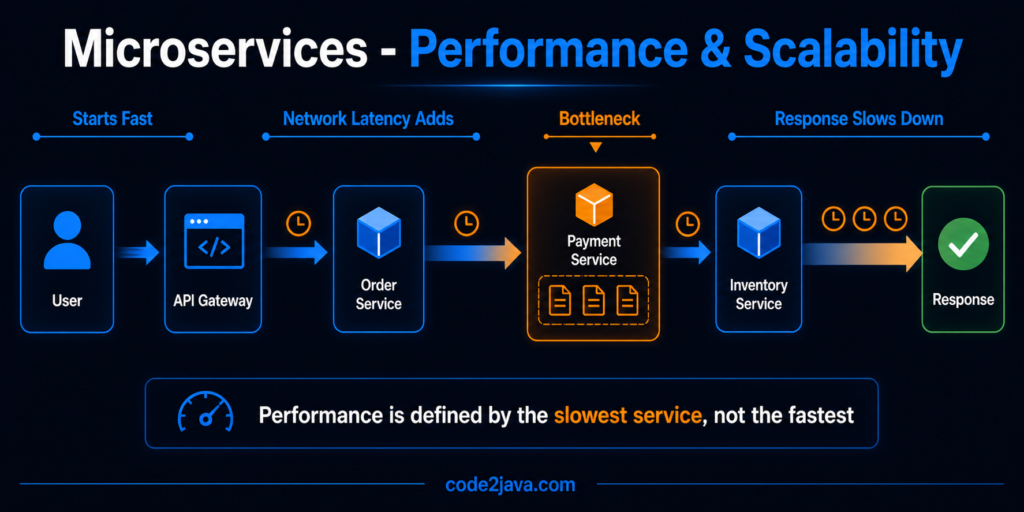
3. Latency Accumulates Across Service Boundaries
In distributed systems, latency is not isolated to a single operation. A request often passes through multiple services before completing. Each service adds its own processing time and network delay.
Even if each service performs efficiently on its own, the total latency increases as these delays accumulate. More importantly, variability compounds. A small delay in one service affects all downstream services.
This creates a system where performance is not defined by the speed of individual components, but by the combined effect of all interactions. The slowest part of the chain determines the overall response time.
4. Thread Blocking Becomes the Limiting Factor
Most microservices systems continue to use a synchronous execution model where each request is handled by a dedicated thread. When a service calls another service, the thread waits for a response before continuing.
Under light load, this model works well. Under heavy load, it becomes a bottleneck. As downstream services slow down, threads spend more time waiting. This increases the number of threads that are idle but still consuming resources.
As more requests arrive, thread pools begin to fill up. Once the pool reaches its limit, new requests are delayed before they can even begin processing. At this stage, the system is no longer limited by CPU capacity but by its ability to manage waiting threads.
This is why systems can appear overloaded even when CPU utilization is not at its maximum.
5. JVM Behavior Becomes Distributed
In a monolith, performance tuning focuses on a single JVM. Memory usage, garbage collection, and thread management are centralized.
In microservices, each service runs in its own JVM. This means that performance characteristics are no longer consistent across the system. One service may be running efficiently, while another experiences memory pressure or GC pauses.
This distributed runtime behaviour introduces variability. Performance issues are no longer global—they are localized to individual services, but their effects are visible across the system.
6. Garbage Collection Introduces Unpredictable Delays
Garbage collection is a normal part of JVM operation, but its impact becomes more noticeable in distributed systems. Each service manages its own memory and runs its own GC cycles.
Reference: https://openjdk.org/jeps/523
When a service experiences high allocation rates, garbage collection runs more frequently. During certain phases, application threads are paused. If this happens while processing a request, it introduces a delay.
In a distributed flow, this delay affects all dependent services. From the outside, this appears as random latency spikes. From the JVM’s perspective, it is expected behavior.
This disconnect makes performance issues harder to trace and understand.
7. Scaling Requires Understanding Dependencies
Microservices allow individual services to scale independently, but system throughput depends on how these services interact.
If one service scales and increases its capacity, it generates more requests for its dependencies. If those dependencies cannot handle the increased load, they become bottlenecks.
This leads to uneven utilization across the system. Some services operate below capacity, while others are overloaded.
Effective scaling requires understanding the entire request flow and ensuring that dependent services can handle increased traffic. Without this, scaling one part of the system does not improve overall performance.
8. Serialization and Data Transfer Add Overhead
In a monolith, data is passed directly in memory. This is efficient and requires minimal processing.
In microservices, data must be converted into a transferable format before being sent over the network. This involves serialization on the sender side and deserialization on the receiver side.
These operations consume CPU and memory. While each individual conversion is small, repeated conversions across multiple services add measurable overhead.
In high-throughput systems, this overhead becomes a significant part of overall processing time.
9. Caching Becomes Fragmented
Caching in a monolith is centralized, a single cache can serve the entire system, improving performance consistently.
In microservices, each service maintains its own cache. There is no shared memory, which leads to duplication of cached data.
This introduces new challenges. Data updates in one service do not automatically invalidate caches in others. As a result, different services may operate on outdated data.
Managing cache consistency becomes part of system design. Without proper handling, caching can introduce inconsistencies instead of improving performance.
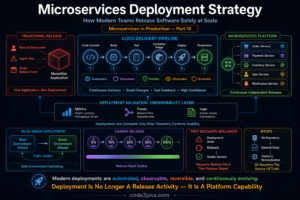
10. From Production Perspective
From a production perspective, performance issues in microservices rarely have a single cause. They emerge from interactions between multiple components.
A slight increase in latency can lead to thread blocking — Thread blocking reduces throughput — Reduced throughput increases queue sizes — Larger queues further increase latency.
At the same time, independent JVM behavior introduces variability across services. One service may experience GC pauses while others continue normally, creating uneven performance.
What makes this challenging is that individual metrics may appear normal. CPU usage may be within limits, and memory may not be exhausted.
Yet the system still feels slow.
This is because performance in distributed systems is determined by how components interact, not just how they perform individually.
Summary
Performance in microservices is fundamentally different from performance in monoliths.
Execution moves from local processing to network-based communication. Latency becomes variable instead of predictable. Runtime behavior becomes distributed instead of centralized.
The system’s performance is defined by the interaction between services, the propagation of latency, and the management of shared resources across independent runtimes.
Scaling improves flexibility, but it does not remove constraints.
Understanding these dynamics is essential for building systems that perform reliably under real-world conditions.