Understanding Micro Services – Part 16 – Deployment Strategy Deep Dive
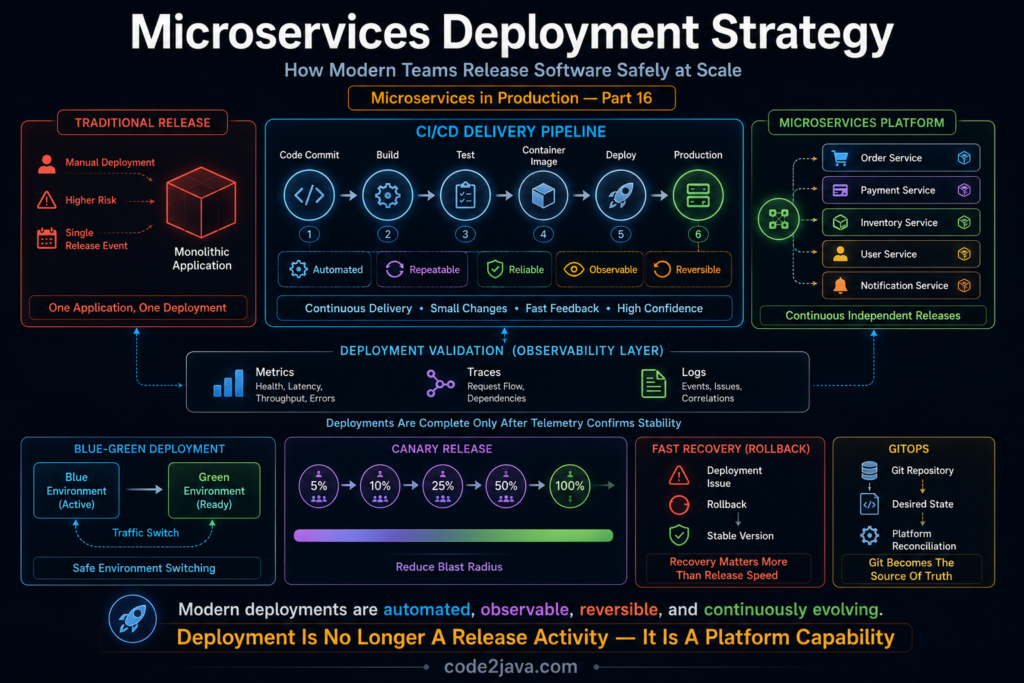
Microservices Deployment Strategy — How Modern Teams Release Software Safely at Scale Building microservices is often perceived as the difficult […]
Microservices Deployment Strategy — How Modern Teams Release Software Safely at Scale Building microservices is often perceived as the difficult […]
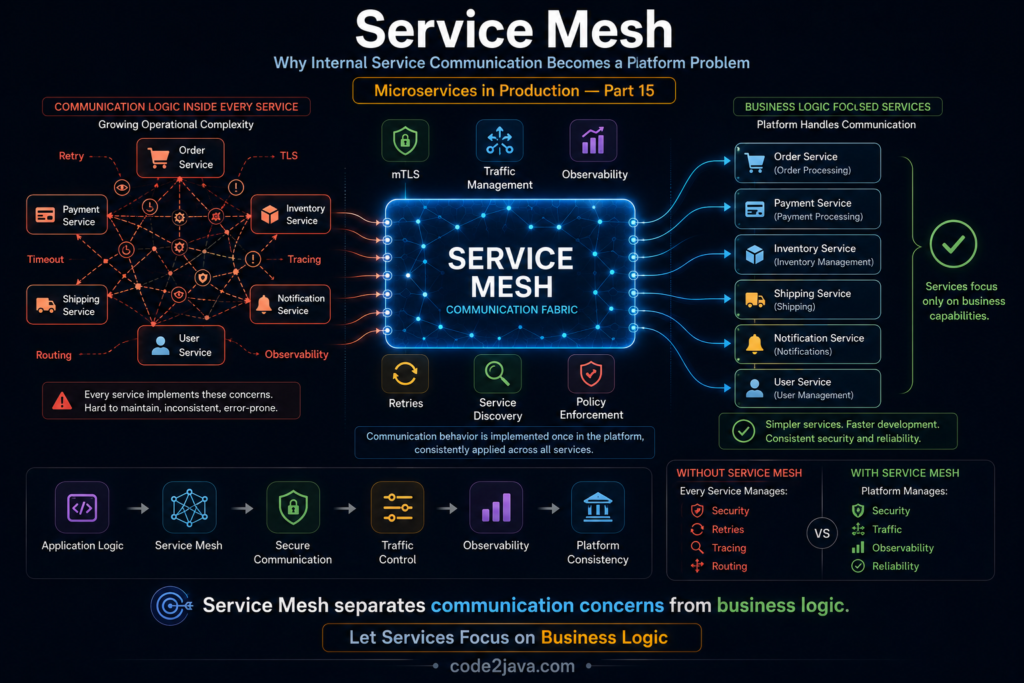
Service Mesh — Why Internal Service Communication Becomes a Platform Problem As organizations adopt microservices, they often focus on the
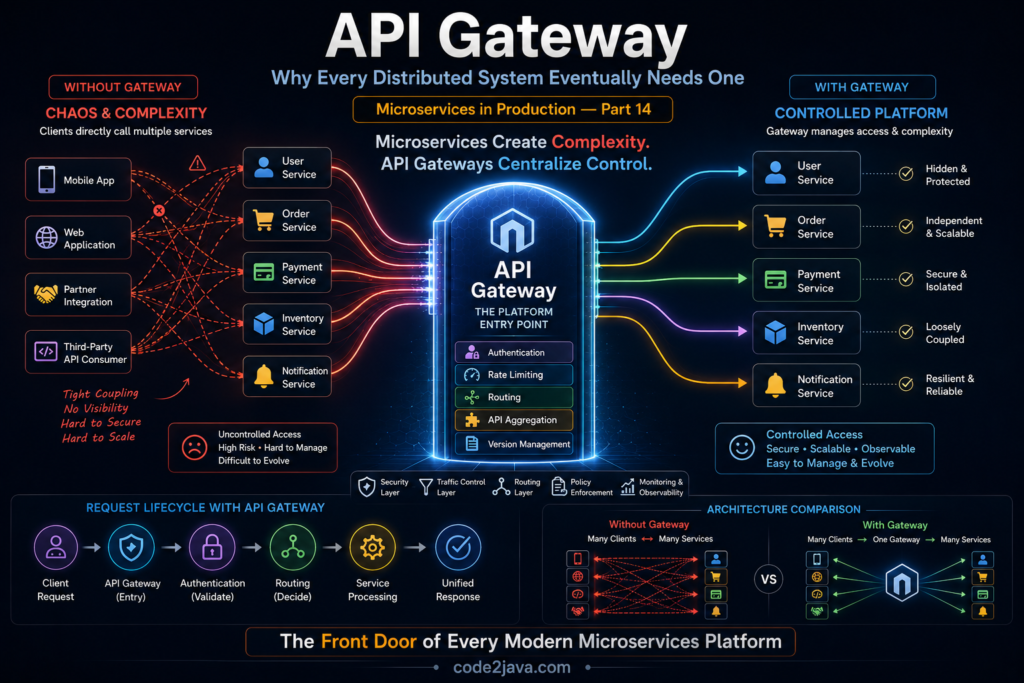
Part 14: API Gateway — Why Every Distributed System Eventually Needs One As organizations move from monolithic applications to microservices,

Observability in Microservices — Why Distributed Systems Become Invisible Without It One of the most interesting things that happens during
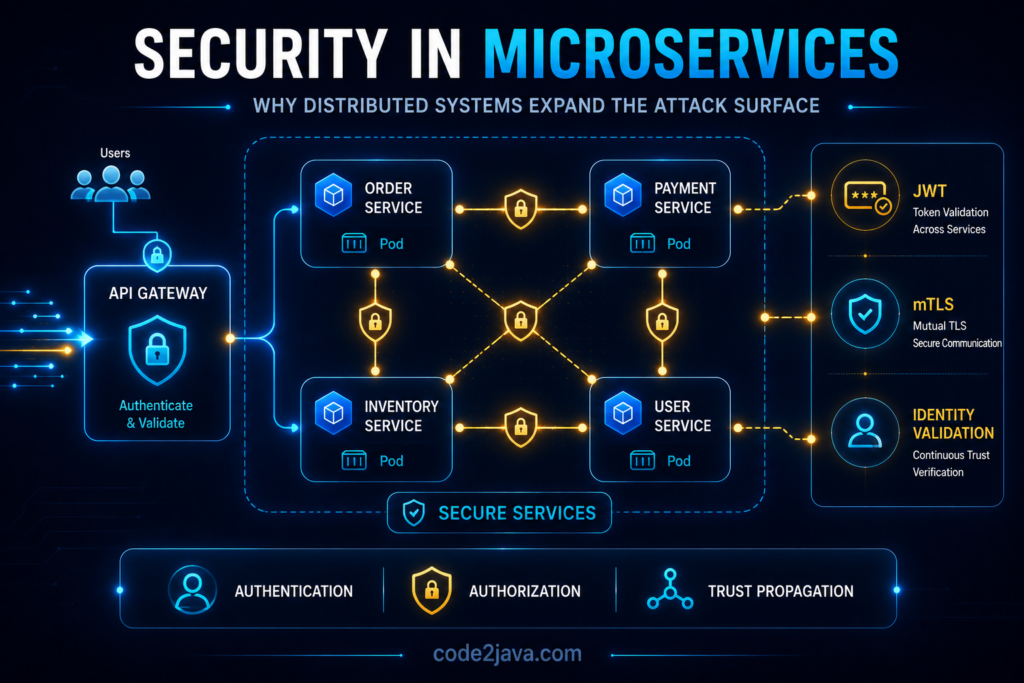
Security in Microservices — Why Security Becomes Harder in Distributed Systems 1. Why Security Changes Completely in Distributed Systems Security
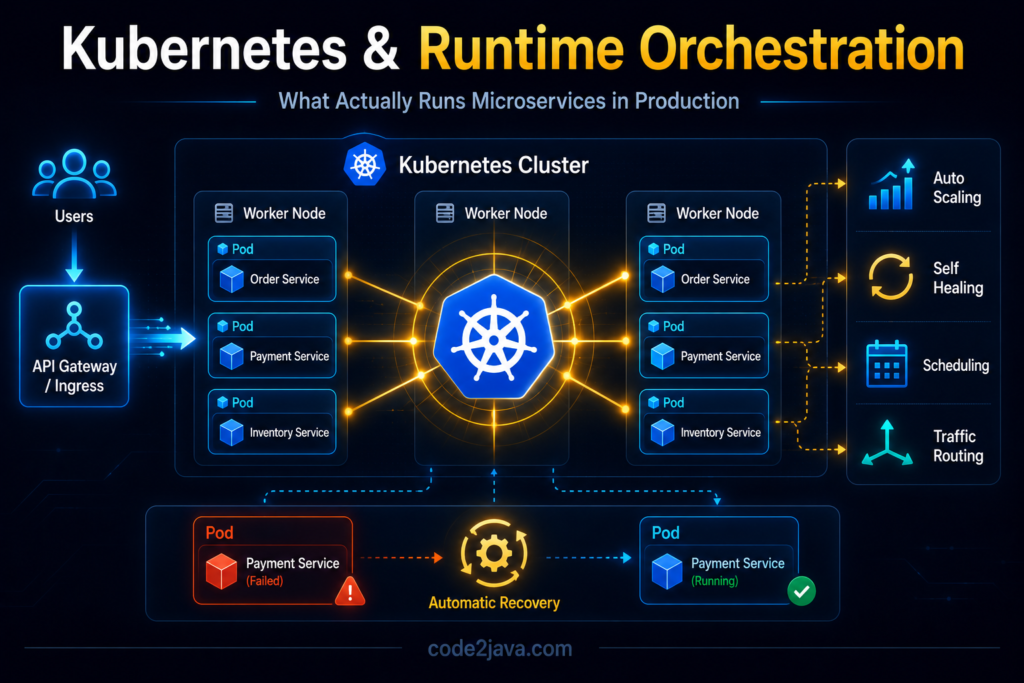
Kubernetes & Runtime Orchestration — What Actually Runs Microservices in Production 1. Why Microservices Eventually Need Orchestration When organizations first
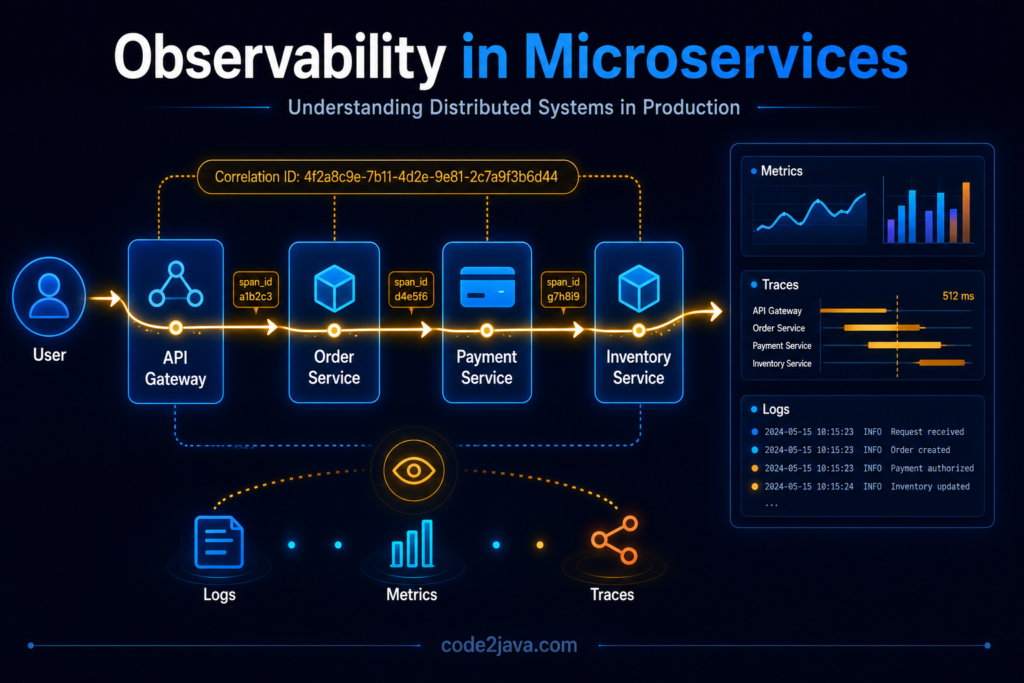
Observability — How You Understand a Distributed System in Production 1. Why Debugging Changes Completely in Microservices One of the
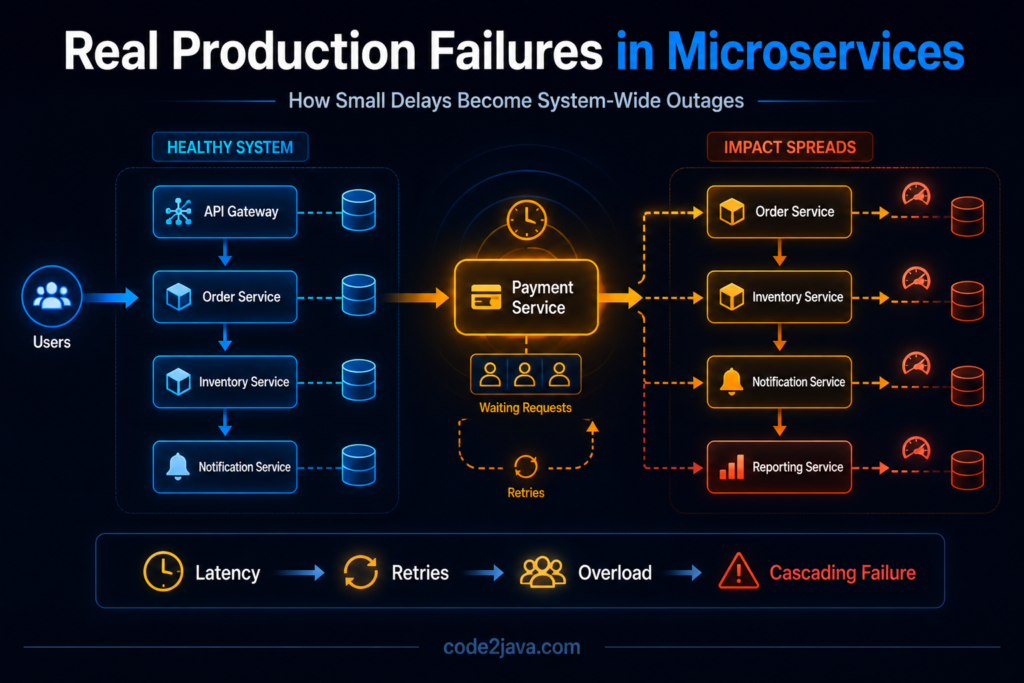
Real Production Failures — What Actually Breaks in Microservices Systems 1. Why Production Failures Never Look Like Architecture Diagrams Most
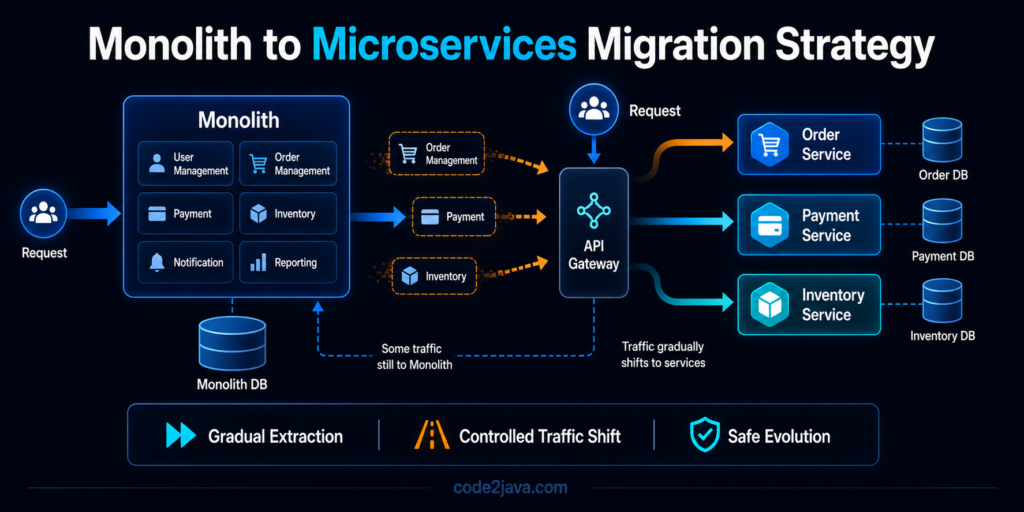
Migration Strategy — How Systems Actually Move from Monolith to Microservices 1. Why Migration Is Harder Than Building Microservices By
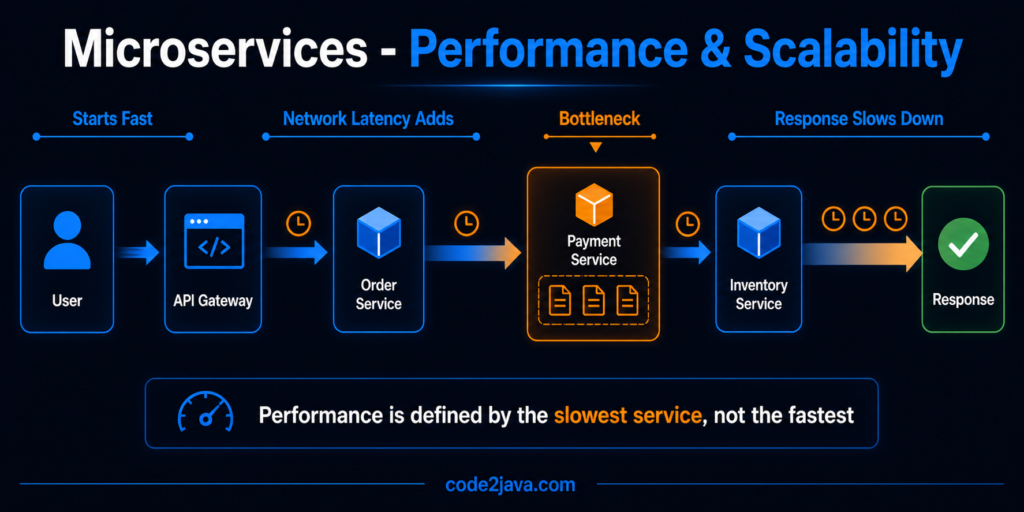
Performance & Scalability — What Actually Happens at Runtime 1. Why Performance Feels Different in Microservices By the time a
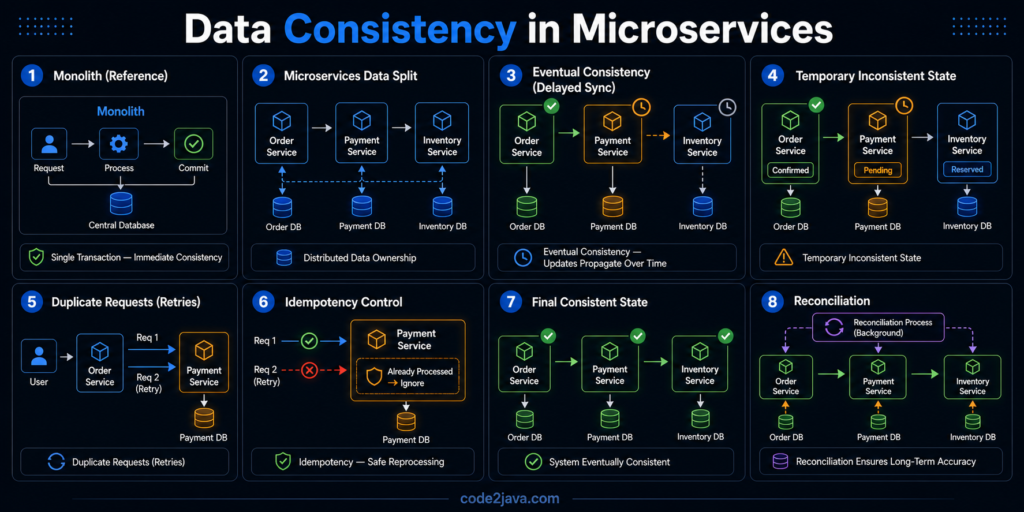
Data Consistency — Why It Becomes the Hardest Problem in Micro Services 1. The Moment Consistency Stops Being Guaranteed Up