The Illusion of Micro Services — What Actually Changes
The Expectation: Breaking the System Will Make It Simpler
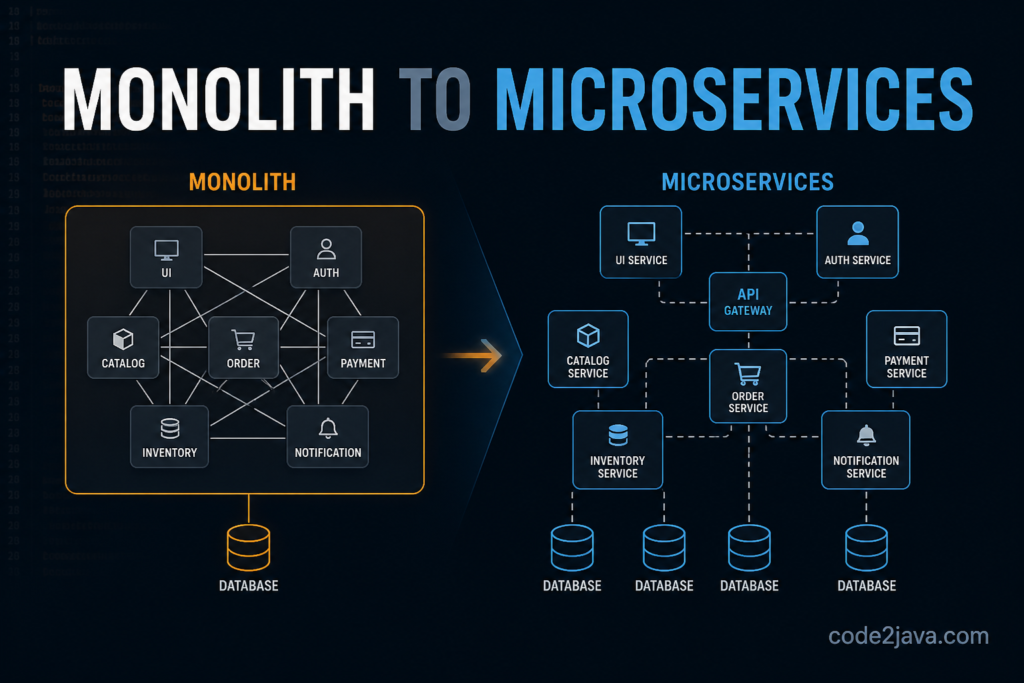
When teams decide to move away from a monolith, the decision rarely comes from curiosity. It usually comes from pressure.
The system has already started showing signs of strain. Things are slowing down, deployments feel risky, and teams are stepping on each other. At that point, microservices begin to look like a clean solution.
The idea feels logical. If one large system is hard to manage, then breaking it into smaller systems should make things easier. Each part can evolve independently. Failures should stay isolated. Scaling should become more controlled.
On paper, everything looks cleaner, but what’s often missed is that microservices don’t actually reduce the complexity of the system, they simply move that complexity into different layers.
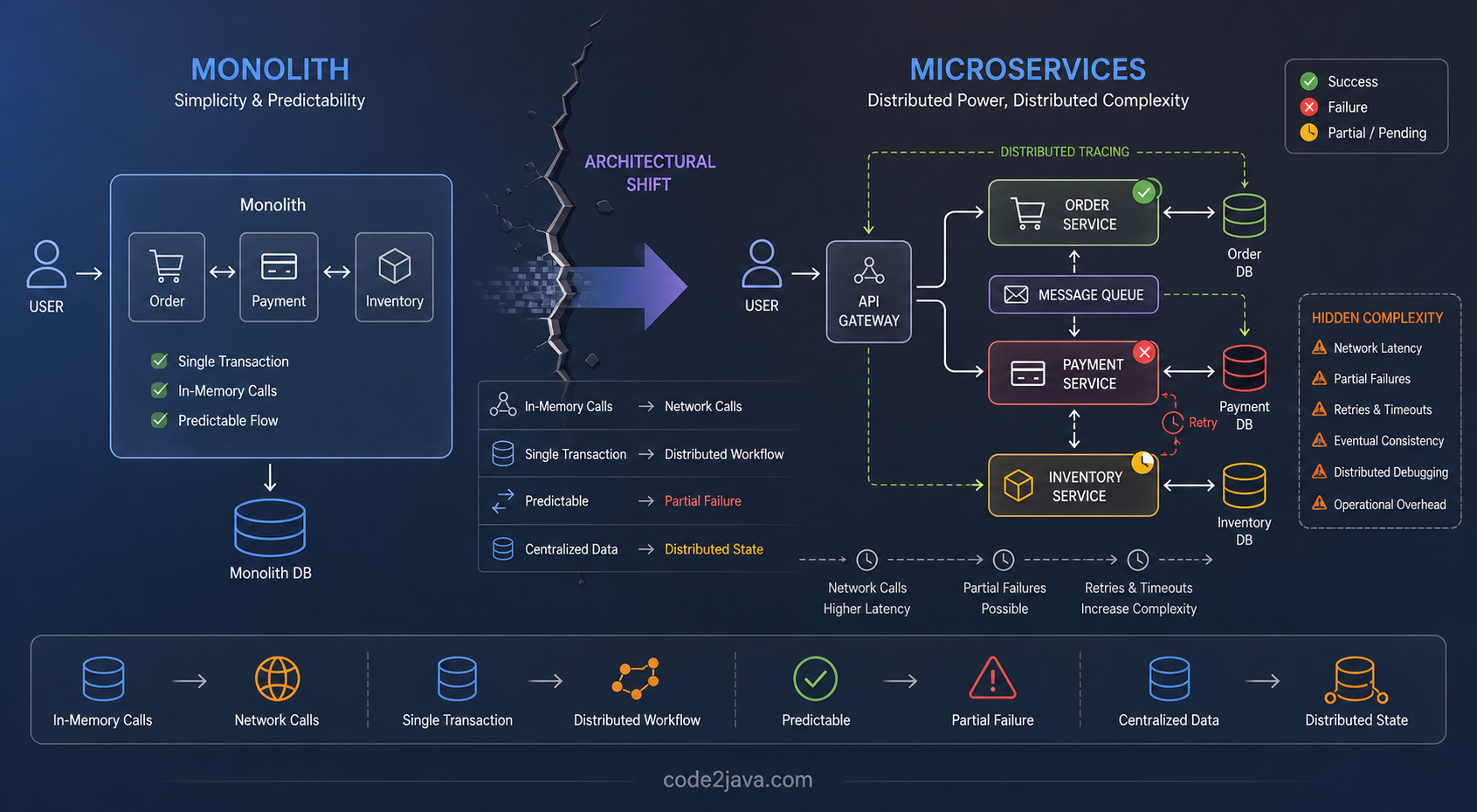
1st Shift: From In-Memory Calls to Network Communication
Inside a monolith, when one part of the system needs something from another, it’s just a method call. It happens instantly, within the same memory space, and almost never fails in unexpected ways.
When the system is split into services, that same interaction becomes a network call.
That change seems small, but it changes the nature of the system – A method call is predictable. A network call is not.
Now every interaction carries uncertainty. It might succeed, it might fail, it might be slow, or it might not return at all. Even when everything is working correctly, latency becomes part of the normal behavior.
So something that used to be guaranteed is now something you have to design around.
2nd Shift: Losing a Single Transaction Boundary
In a monolith, complex operations feel safe because they run inside a single transaction. If a flow involves multiple steps, they either all succeed or all fail together. That gives a strong sense of control over system behaviour.
Once you move to microservices, that safety net disappears. Each service manages its own data and commits its own changes. There is no shared transaction that connects them. So now, a flow can partially succeed.
An order might be created. A payment might fail. Inventory might already be reserved. Nothing is technically broken, but the system is now in a state that didn’t exist before.
This is where the thinking has to change. Instead of relying on rollback, you now have to design how the system recovers.
3rd Shift: Failure Is No Longer Simple
In a monolith, failure is easy to reason about. Either the request completes successfully, or it fails and rolls back.
In a micro services system, failure becomes layered. A request might succeed in one service, fail in another, and timeout in between. It might even be retried automatically, creating multiple attempts for the same operation.
This means the system can exist in intermediate states that were never visible before.
Handling these states is not optional. It becomes part of the system design. You are no longer just writing business logic. You are defining how the system behaves when things don’t go as expected.
4th Shift: Latency Becomes a System Property
In a monolith, latency is mostly tied to how long the code takes to execute and how fast the database responds.
In microservices, latency becomes something that flows through the entire system. A single request may pass through multiple services. Each one adds its own delay. Even if each step is fast, the total time increases. More importantly, latency becomes uneven. If one service slows down, everything behind it slows down. If one dependency is unstable, it affects the entire request flow.
The system starts behaving like a chain, where the weakest link(service) determines the overall performance.
5th Shift: Scaling Requires Coordination
One of the strongest arguments for microservices is independent scaling.
Athough it is true that individual services can scale separately. But real systems are not isolated pieces. They are connected.
If one service handles more traffic, it pushes more load onto the services it depends on. If those services are not prepared, they become bottlenecks. So scaling is no longer just about increasing capacity. It becomes about understanding how load moves through the system.
The system must scale as a whole, not just in parts.
6th Shift: Data Stops Being Centralized
In a monolith, data lives in one place. If you want to understand the system, you query the database and get a consistent answer.
In microservices, data is distributed. Each service owns its own data, and there is no single place where everything comes together in real time.
To understand the full state, you often need to combine information from multiple services. This introduces a new challenge. The system’s state is no longer immediately consistent everywhere. It is eventually consistent, and sometimes temporarily incomplete.
This makes reporting, debugging, and auditing more complex.
7th Shift: Debugging Becomes a System Problem
In a monolith, debugging is local. You look at logs, follow the execution path, and find the issue.
In microservices, a single request moves across multiple services. If something goes wrong, the information is spread across different systems. You have to trace the request across boundaries, correlate logs, and reconstruct what happened. Without proper tracing and observability, this becomes very difficult.
At this point, debugging is no longer about code. It is about understanding the system as a whole.
From Production Perspective
In real production environments, the move to microservices rarely feels like an immediate improvement.
- Systems often become harder to manage at first.
- Latency increases because of network communication.
- Failures become less predictable.
- Issues take longer to diagnose because they span multiple services.
The system is not worse, but it is more complex. Stability comes back only after introducing things that were not needed before—clear retry strategies, proper timeouts, circuit breakers, and strong observability.
Microservices don’t simplify the system, they require a higher level of discipline to manage it.
Summary
Moving to microservices changes how a system behaves at every level. What used to be simple and predictable becomes distributed and uncertain.
You move from:
- direct calls to network communication
- single transactions to distributed workflows
- clear failures to partial outcomes
- centralized data to distributed state
The system becomes more flexible, but also harder to reason about.
Understanding this shift is critical.
Because microservices are not just an architectural change—they are a change in how you think about building and operating systems.