How Systems Actually Fail — The Reality of Distributed Failures
1. When Everything Works… Until It Doesn’t
By the time a system reaches microservices, it usually looks clean on diagrams. Services are separated, responsibilities are clear, and deployments are independent. From an architectural standpoint, everything appears structured and scalable.
Most of the time, the system does work. Requests flow across services, responses come back, and data moves as expected. This is exactly what makes failures in microservices difficult to anticipate.
Failures do not show up as immediate crashes. Instead, they begin as subtle disruptions in flow.
A service slows down slightly, a dependency starts timing out, or a retry mechanism kicks in more often than expected. Individually, these are small issues. Together, they begin to change how the system behaves.
2. A “Simple” Request Is No Longer Simple
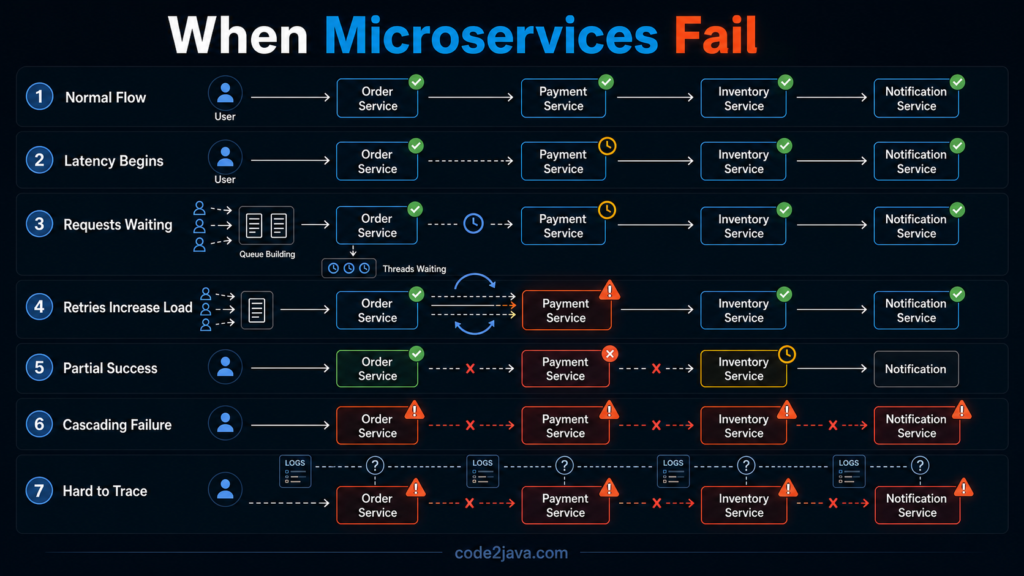
What appears to be a single request from the outside is, in reality, a sequence of dependent operations across multiple services. An order placement, for example, is no longer a single execution path. It involves multiple services coordinating in sequence—order creation, payment processing, inventory reservation, and notification.
Each step depends on the previous one, and each step introduces its own latency and failure possibility. The request is no longer atomic. It becomes a chain of interactions, where each link must hold for the overall flow to succeed.
This change is fundamental. The system is no longer executing a request—it is orchestrating it.
3. Latency Does Not Stay Local — It Spreads
One of the earliest failure patterns is not failure at all, but delay.
When a service starts responding slowly, even without failing, the impact does not stay isolated. The service calling it has to wait. While it waits, its threads are occupied. As more requests arrive, more threads enter the same waiting state.
Over time, this creates pressure across the system. Thread pools begin to fill up, request queues start forming, and response times increase. Eventually, timeouts appear, even in services that are functioning correctly.
The key point is that latency is not contained. It propagates. A delay in one service becomes a delay everywhere downstream.
4. Partial Success Becomes a Normal State
In a distributed system, operations no longer succeed or fail as a whole. They can succeed in parts.
A request may pass through several services, with each one committing its work independently. If a failure occurs midway, the system is left in a partially completed state. Some steps are done, others are not.
This introduces a new kind of complexity. The system must now recognize and resolve these intermediate states. What was previously handled by a single transaction rollback must now be handled through explicit logic.
The system is no longer just executing operations. It is responsible for maintaining correctness across incomplete executions.
5. Retries Can Become a Source of Failure
Retries are often introduced as a safety mechanism. When a request fails, retrying it can recover from temporary issues.
However, in a distributed system, retries do not exist in isolation. When a service slows down or starts failing, multiple upstream services may begin retrying simultaneously. Each retry adds additional load to the same struggling service.
Over time, this creates amplification. The system starts generating more traffic than the original workload. Instead of recovering, the service becomes further overloaded.
This is one of the most counterintuitive aspects of distributed systems. Mechanisms designed for resilience can, under pressure, contribute to failure.
6. Failures Do Not Stay Contained — They Cascade
As latency increases and retries build up, the system begins to experience cascading effects.
A single slow service causes upstream services to wait. Waiting consumes threads. As thread pools fill up, those services stop responding to their own callers. The failure spreads outward, affecting more parts of the system.
At this point, the system does not fail because everything is broken. It fails because everything is connected. Dependencies create pathways through which failure can propagate.
Cascading failure is not a sudden event. It is a progression, where one weakness gradually impacts the entire system.
7. Duplicate Processing Becomes Inevitable
In an environment where retries are common and responses are not always reliable, duplicate processing becomes unavoidable.
If a request times out, the system may retry it. But the original request might still complete. Without safeguards, the same operation is executed more than once.
This leads to inconsistencies such as duplicate transactions, repeated updates, or conflicting states. These are not edge cases—they are natural outcomes of distributed communication.
Handling duplicates requires intentional design. Without it, the system cannot guarantee correctness.
8. Debugging Moves from Code to System
When failures occur in a monolith, the problem is usually localized. Logs, stack traces, and execution paths are all within a single system.
In microservices, a single request may pass through multiple services. Each service logs independently, and failures may occur at different points in time.
Understanding what happened requires correlating events across systems. Without proper tracing, it becomes difficult to reconstruct the sequence of operations.
Debugging is no longer about reading code or logs in isolation. It becomes an exercise in understanding how the system behaves as a whole.
9. From Production Perspective
From a production perspective, failures in microservices rarely appear as clear-cut incidents. They build gradually –
- A service slows down slightly
- Retry rates increase
- Latency spreads across services
By the time visible errors appear, the system is already under stress.
What makes this challenging is that symptoms often appear far from the root cause. The service showing errors may not be the one causing the issue.
Stability in such systems does not come from eliminating failures. It comes from controlling how failures propagate and how the system responds under stress.
Summary
In microservices, failure is not a single event. It is a sequence of effects that build on each other. A small delay can lead to increased latency, which leads to retries, which leads to overload, which eventually leads to system-wide failure.
The system does not break because one component fails. It breaks because the system allows failure to spread.
Understanding these patterns is essential. Without that understanding, microservices systems remain fragile under real-world conditions.