Design Patterns — How Microservices Actually Survive in Production
1. Why Patterns Become Necessary (Not Optional)
By the time a system reaches the failure modes discussed earlier, one thing becomes clear. The system is not failing because developers wrote incorrect logic. It is failing because the architecture does not handle distributed behaviour properly.
In a monolith, correctness is enforced by the platform itself. Transactions guarantee consistency. Method calls guarantee execution. Failures are contained within a single process.
Once the system becomes distributed, those guarantees disappear.
What replaces them is not another framework or tool. It is a set of design patterns that define how the system should behave under uncertainty.
These patterns are not optimizations. They are control mechanisms. Without them, the system behaves unpredictably under load and failure.
2. The Core Problem: You No Longer Control Execution
Before going into patterns, it is important to understand what has fundamentally changed.
In a monolith, execution is controlled. When a function is called, it executes immediately. When a transaction starts, it either commits or rolls back.
In microservices, execution is indirect, a service sends a request and waits. The response may come late, may fail, or may not come at all. Multiple services may act independently without a central coordinator.
This means the system must be designed to handle incomplete, delayed, and repeated execution.
Design patterns exist to bring structure to this uncertainty.
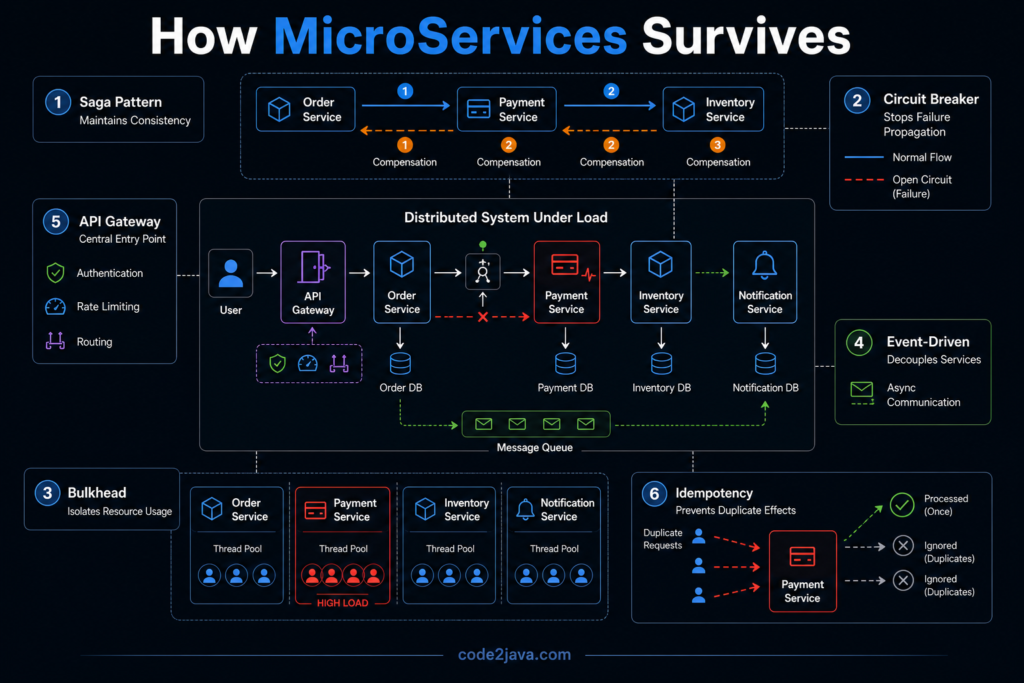
3. Managing Distributed Transactions: The Saga Pattern
One of the first problems that appears in microservices is the loss of a single transaction boundary.
Operations that were once atomic are now spread across services. Each service updates its own data independently. There is no shared rollback mechanism. This creates situations where part of the operation succeeds while another part fails.
The Saga pattern exists to handle this exact problem. Instead of relying on a single transaction, the system breaks the operation into a sequence of steps. Each step completes independently and moves the system forward.
If a step fails, the system does not roll back automatically. Instead, it executes compensating actions to undo the completed steps.
For example, if a payment fails after an order is created, the system must explicitly cancel the order and release any reserved resources.
What makes Saga important is not just the sequence, but the responsibility it introduces.
The system must now:
- Track the state of each step
- Decide what to do on failure
- Ensure compensation is reliable
This shifts the responsibility of consistency from the database to the application.
4. Controlling Failure Propagation: The Circuit Breaker
In distributed systems, failures rarely stay isolated. When one service slows down or becomes unavailable, other services continue calling it. These calls wait, retry, and eventually consume resources. This is how small failures turn into system-wide issues.
The Circuit Breaker pattern is designed to stop this behaviour early.
Instead of continuously calling a failing service, the system monitors failures. When failures cross a threshold, it stops making calls temporarily. During this period, the system can either return a fallback response or fail fast.
Internally, this changes how the system behaves under stress. Instead of allowing threads to block indefinitely, the system actively prevents resource exhaustion.
Circuit Breaker Pattern does not fix the failing service. It prevents the failure from spreading.
5. Isolating Resource Usage: The Bulkhead Pattern
One of the key reasons cascading failures occur is shared resource usage. When multiple operations share the same thread pool or connection pool, a slow dependency can consume all available resources.
The Bulkhead pattern addresses this by isolating resources.
Different parts of the system are given separate pools. For example, calls to external services may use a different thread pool than internal processing. This ensures that a failure in one area does not affect others.
The idea is similar to compartments in a ship. If one section is flooded, the entire ship does not sink.
In microservices, this isolation prevents one failing dependency from taking down the entire system.
6. Handling Communication Flexibility: Event-Driven Architecture
One of the underlying causes of failure in microservices is tight coupling through synchronous communication. When one service calls another and waits for a response, it becomes dependent on that service’s availability and performance.
Event-driven architecture changes this interaction model. Instead of direct calls, services communicate through events. One service emits an event, and others react to it independently.
This removes immediate dependency between services. Internally, this introduces a different execution model.
- Operations become asynchronous
- Services process events at their own pace
- Failures do not immediately block upstream systems
However, this also introduces complexity in tracking system state, since operations are no longer linear.
Event-driven systems trade immediate consistency for resilience and scalability.
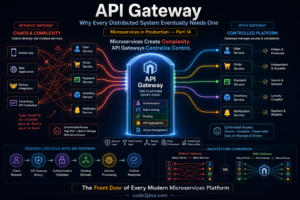
7. Managing Entry Complexity: The API Gateway
As systems grow, the number of services increases. Without control, clients would need to interact with multiple services directly. This creates complexity in communication, security, and version management.
The API Gateway pattern provides a single entry point into the system.
Instead of clients calling multiple services, they interact with the gateway. The gateway routes requests to the appropriate services and may aggregate responses.
This simplifies client interaction and centralizes cross-cutting concerns like authentication, rate limiting, and logging.
Internally, this reduces coupling between clients and services, but introduces a new critical component that must be highly available.
8. The Hidden Requirement: Idempotency
Across all these patterns, one requirement keeps appearing repeatedly—idempotency.
In distributed systems, operations may be retried, messages may be delivered multiple times, failures may lead to reprocessing. If operations are not idempotent, repeated execution leads to inconsistent results.
For example, processing the same payment twice must not result in duplicate transactions. This requires designing operations in a way where repeating them produces the same outcome.
Idempotency is not a pattern on its own, but it is a foundational requirement for all distributed behavior.
9. From Production Perspective
In production environments, introducing these patterns is not an optimization step, it is a stabilization phase.
Systems that initially move to microservices often experience failures similar to those described earlier—latency issues, retries, partial states, and cascading failures.
These patterns are introduced gradually as those issues appear.
- Saga handles incomplete workflows
- Circuit Breaker prevents overload
- Bulkhead protects resources
- Event-driven architecture reduces tight coupling
Over time, the system becomes more resilient, not because failures disappear, but because the system learns to contain and manage them.
Summary
Microservices do not work reliably by default, they require deliberate design to handle distributed behaviour.
The patterns discussed are not optional improvements. They are mechanisms that define:
- how the system handles failure
- how it maintains consistency
- how it protects itself under load
Without these patterns, microservices systems remain fragile.
With them, the system becomes capable of operating under real-world conditions where delays, failures, and retries are normal.