Kubernetes & Runtime Orchestration — What Actually Runs Microservices in Production
1. Why Microservices Eventually Need Orchestration
When organizations first move from monoliths to microservices, most of the focus stays on application architecture. Teams spend time designing service boundaries, APIs, communication patterns, and deployment pipelines. Initially, this feels manageable because the number of services is still relatively small.
Over time, the system grows far beyond what teams originally imagined.
What started as a few independent services slowly becomes dozens or even hundreds of deployable components running across multiple environments. Each service may have several runtime instances handling traffic simultaneously. Some services process APIs, others consume events, while background jobs continuously execute asynchronously across the platform.
At this stage, the architecture itself is no longer the hardest part, the real challenge becomes operational management.
Services fail unexpectedly, traffic patterns fluctuate continuously, infrastructure nodes become unavailable, deployments happen multiple times a day, scaling requirements change dynamically depending on production load.
Managing all of this manually quickly becomes impossible, this is the operational problem Kubernetes was designed to solve.
2. Why Containers Changed Distributed Systems
Before containers became mainstream, deploying distributed systems was significantly more painful than many teams remember today.
Applications often behaved differently between development, staging, and production environments because runtime dependencies varied across systems. Small operating system differences, missing libraries, or inconsistent runtime versions frequently caused unexpected production behavior.
As systems became larger, these inconsistencies slowed down deployments and increased operational risk.
Containers fundamentally changed the ways of deployment, ensuring consistency and reducing the operational overhead.
Instead of deploying applications directly onto infrastructure, teams package applications together with their runtime dependencies into isolated execution environments. The same container image runs consistently across laptops, test environments, cloud platforms, and production clusters.
This consistency became one of the major reasons microservices adoption accelerated rapidly across the industry.
However, containers only solved one part of the problem. They standardised runtime packaging, but they did not solve orchestration, scaling, scheduling, networking, or automated recovery. Once organisations started running hundreds of containers simultaneously, a new operational challenge appeared.
Teams now needed a platform capable of managing distributed runtime behaviour automatically.
3. Kubernetes Changed Infrastructure from Static to Dynamic
Traditional infrastructure management treated servers as long-running machines that engineers configured manually.
Applications were deployed onto specific servers, operational teams monitored those machines directly, and failures were usually handled through human intervention. This approach worked reasonably well for smaller systems, but it became difficult to sustain as microservices environments expanded.
Kubernetes introduced a completely different operational model – Instead of managing infrastructure manually, engineers define the desired state of the system declaratively. Kubernetes continuously works to maintain that state automatically.
For example, if the platform should always run five instances of a service, Kubernetes monitors the environment continuously and recreates missing instances whenever failures occur.
This changes how infrastructure behaves operationally. Servers stop being permanent runtime environments, workloads become temporary execution units that Kubernetes can schedule, move, replace, or restart dynamically based on cluster conditions.
The system no longer assumes stability at the infrastructure layer. Instead, it assumes instability will happen regularly and focuses on automated recovery.
That mindset shift is one of the most important conceptual changes in modern distributed systems.
4. Pods Are More Important Than Containers
One of the most common misconceptions about Kubernetes is that containers are the primary execution unit.
Operationally, Kubernetes manages pods.
A pod represents one or more tightly coupled containers sharing networking and storage resources. Most microservices run inside single-container pods, but Kubernetes schedules and manages the pod as a complete runtime unit.
This distinction matters because pods are intentionally temporary.

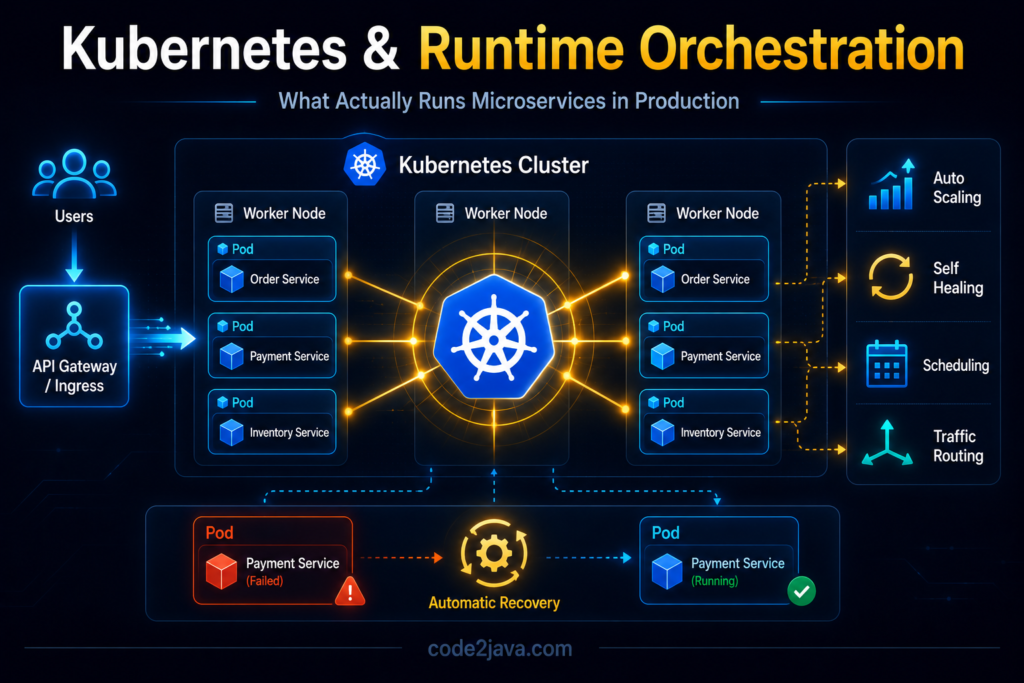
This image explains how Kubernetes orchestrates microservices by running containers inside pods across multiple worker nodes within a cluster.
It also highlights Kubernetes features like traffic routing, pod management, and automatic recovery when a pod fails.
If a pod fails, Kubernetes usually replaces it entirely instead of attempting to repair it manually. This creates a very different operational mindset compared to traditional infrastructure management.
The platform treats workloads as disposable runtime instances rather than permanent servers. As a result, applications running inside Kubernetes environments must tolerate restarts, rescheduling, and temporary infrastructure instability continuously.
Systems designed with assumptions about stable infrastructure often struggle badly after moving into Kubernetes environments because the platform behaves far more dynamically than traditional server deployments.
5. Scheduling Is Actually a Runtime Performance Problem
At first glance, Kubernetes scheduling appears simple: A pod needs to run somewhere, and Kubernetes selects an available node. In reality, scheduling becomes one of the most important runtime behaviours inside large distributed systems.
The scheduler continuously makes placement decisions based on:
- CPU availability
- memory pressure
- node health
- workload distribution
- affinity rules
- infrastructure constraints
Under production load, these placement decisions directly affect system performance.
For example, placing heavily communicating services far apart inside the cluster may increase network latency unexpectedly. Concentrating resource-intensive workloads on the same nodes may create CPU contention and memory pressure. Uneven workload distribution can overload parts of the infrastructure while other nodes remain underutilised.
At scale, Kubernetes scheduling becomes part of runtime system behaviour rather than just deployment automation.
The orchestration platform itself starts influencing application performance characteristics.
6. Autoscaling Solves Capacity Problems — Not Architectural Bottlenecks
Autoscaling is one of the most widely misunderstood concepts in Kubernetes environments. Many teams initially assume autoscaling automatically guarantees scalability. The expectation is that when traffic increases, Kubernetes simply creates more instances and the system continues operating smoothly.
Real production systems behave differently. Autoscaling only increases the number of workload instances, it does not remove dependency bottlenecks inside the architecture.
For example, scaling API services aggressively may increase pressure on downstream databases, queues, caches, or dependent services that cannot scale at the same rate. Instead of improving performance, autoscaling may amplify system instability by generating additional downstream load.
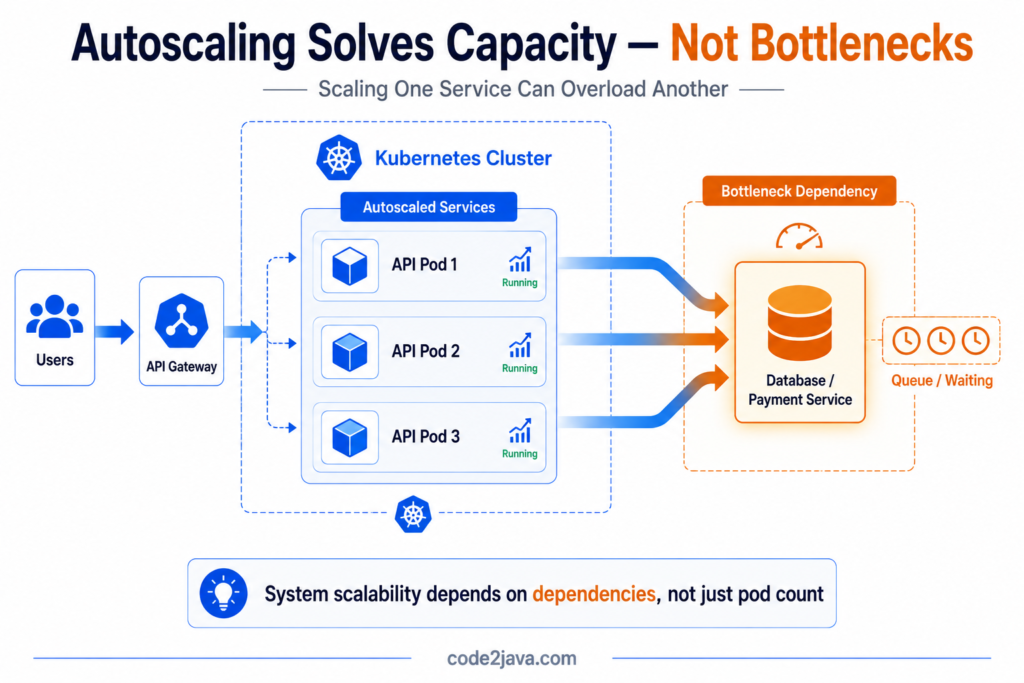
This creates a very important realisation.
Scalability is never isolated to one service. Distributed systems only scale reliably when dependencies, infrastructure capacity, networking behaviour, and resource management evolve together. Otherwise, autoscaling simply moves bottlenecks from one layer of the architecture into another.
7. Networking Becomes One of the Hardest Operational Problems
Inside monoliths, communication happens within a single process boundary. Whereas inside Kubernetes environments, every interaction becomes network-driven.
Services communicate across pods, nodes, ingress layers, proxies, service meshes, and internal cluster networking components. Kubernetes abstracts much of this complexity through service discovery and networking primitives, but the runtime behaviour remains highly distributed underneath.
This introduces new operational realities.
Latency may now depend on pod placement, proxy overhead, DNS resolution timing, or cluster congestion. Small networking delays can propagate across multiple services and gradually impact the entire request flow.
At large scale, networking becomes one of the hardest runtime problems to reason about because failures are often intermittent and difficult to reproduce consistently.
Architecturally, the system may appear clean and modular, but operationally, the runtime communication layer becomes extremely dynamic.
8. Why CrashLoopBackOff Happens So Often
One of the most recognisable Kubernetes operational symptoms is CrashLoopBackOff.
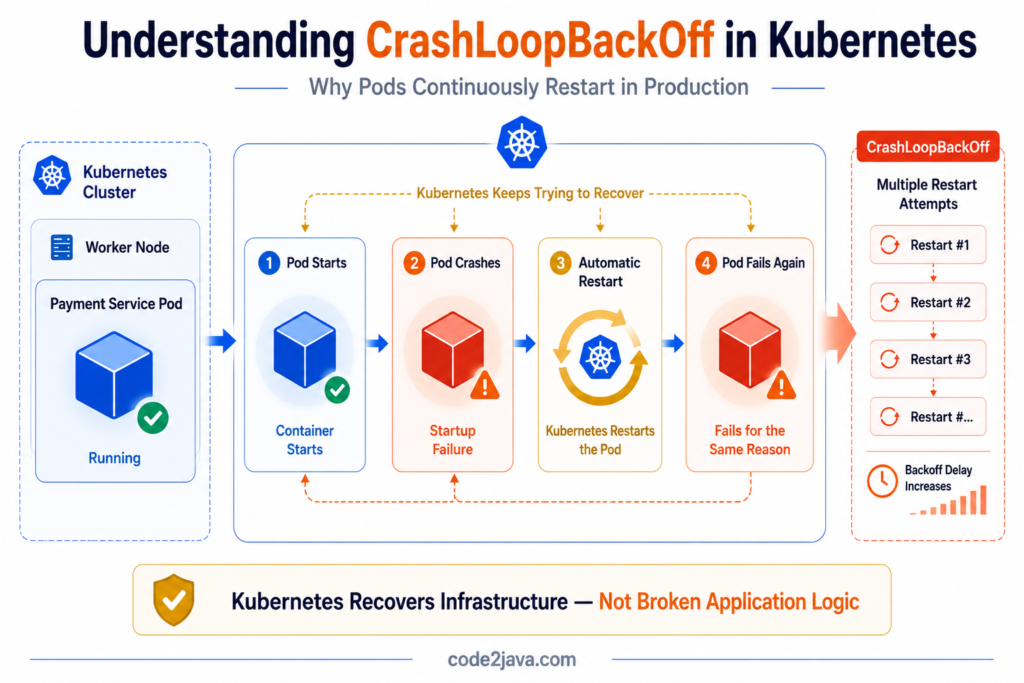
This occurs when workloads repeatedly start, fail, restart, and fail again in continuous cycles.
From the outside, this often looks like a deployment problem. Internally, the causes are usually much broader.
Applications may fail because dependencies are unavailable during startup. Configuration values may be incorrect. Memory limits may be too restrictive. Readiness checks may fail repeatedly while services are still initializing.
Kubernetes responds exactly as designed. It continuously attempts recovery by restarting unhealthy workloads automatically.
If the underlying problem persists, the restart cycle continues indefinitely. This creates situations where applications appear deployed successfully while remaining operationally unavailable in practice.
Understanding these runtime lifecycle patterns becomes essential because orchestration platforms aggressively automate both recovery and instability simultaneously.
9. Resource Limits Directly Shape Runtime Behaviour
Kubernetes heavily relies on CPU and memory constraints to maintain cluster stability. These limits protect shared infrastructure from resource exhaustion, but they also influence runtime behaviour directly.
If memory limits are configured too aggressively, workloads experience OOMKilled failures when memory consumption exceeds allowed thresholds. If CPU throttling becomes excessive under load, services may appear unexpectedly slow even though application logic itself remains efficient.
This creates an important operational reality.
Many performance issues inside Kubernetes environments are not caused by bad application code, they are caused by orchestration-level resource enforcement decisions happening underneath the runtime.
At scale, understanding infrastructure constraints becomes just as important as understanding application behavior.
10. Kubernetes Increases Operational Capability — and Operational Complexity
Kubernetes solves many operational problems extremely well, but it also introduces substantial platform complexity. Teams now need to understand:
- orchestration behavior
- networking layers
- scaling policies
- runtime scheduling
- container lifecycle management
- infrastructure reconciliation
- distributed observability
This complexity is one of the biggest reasons organizations struggle after adopting microservices too aggressively. The architecture becomes easier to scale conceptually, but significantly harder to reason about operationally.
Success in Kubernetes environments requires strong platform engineering discipline alongside application engineering expertise.
Modern distributed systems are no longer just software architectures, they are operational runtime platforms.
11. From Production Perspective
From a production perspective, Kubernetes fundamentally changes how engineers think about infrastructure reliability.
Servers stop being permanent assets. Workloads become temporary runtime instances managed continuously by orchestration policies. Infrastructure failures become expected operational events instead of exceptional incidents.
Stable systems are no longer built by preventing failures entirely, they are built by designing architectures capable of recovering automatically while infrastructure changes constantly underneath them.
Kubernetes provides the automation layer required to operate distributed systems at scale, but only when teams understand how orchestration, scaling, networking, scheduling, and runtime behaviour interact under production pressure.
At large scale, the operational platform becomes just as important as the application architecture itself.
Summary
Microservices introduced architectural flexibility, but they also created enormous operational complexity.
Containers solved runtime consistency problems by standardising application packaging across environments. Kubernetes extended that model by introducing orchestration capable of managing distributed workloads dynamically.
However, orchestration also introduced new runtime realities:
- dynamic scheduling
- distributed networking
- autoscaling behavior
- automated recovery loops
- infrastructure-level resource enforcement
Kubernetes does not eliminate operational complexity, it automates and centralises complexity that would otherwise become impossible to manage manually at scale.
Understanding this orchestration layer is critical because modern distributed systems are no longer defined only by application code. They are equally defined by how the runtime platform behaves under real production conditions.