Production Problem: Latency Spike Caused by a “Simple” HashMap
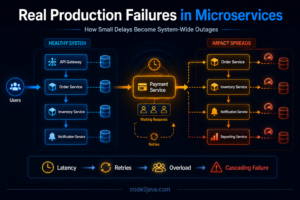
A payment aggregation service handling tens of thousands of transactions per second began exhibiting unpredictable latency spikes. CPU usage increased, but only during peak traffic windows. Thread dumps showed no obvious locks or blocking I/O—most time was spent inside HashMap operations.
The root cause was not immediately visible from application logic. The service used a HashMap to maintain intermediate aggregation state keyed by transaction identifiers. However, these identifiers were derived from a composite object whose hashCode() implementation produced clustered values.
Internally, this violated HashMap’s core assumption of uniform key distribution. Instead of evenly spreading entries across buckets, many keys landed in the same bucket. This transformed what should have been constant-time lookups into traversal-heavy operations, increasing latency and CPU consumption under load.
Internal Working: How HashMap Actually Stores and Retrieves Data
HashMap is implemented as an array of nodes where each index represents a bucket. The placement of a key depends on a hash computation followed by a bitwise operation to determine the bucket index.
The hashing logic is implemented in the OpenJDK source:
https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/HashMap.java
Instead of directly using hashCode(), HashMap applies a hash spreading function that mixes higher bits into lower bits. This is necessary because the index calculation uses only the lower bits of the hash. Without this step, poorly implemented hashCode() methods would lead to excessive collisions.
The index is calculated using (n - 1) & hash, where n is the current capacity. Because the capacity is always a power of two, this operation efficiently maps the hash to a valid index without using modulo arithmetic.
When inserting an entry, if the bucket is empty, the entry is stored directly. If the bucket already contains entries, HashMap must resolve the collision. Prior to Java 8, collisions were handled using linked lists. From Java 8 onward, if the number of entries in a bucket exceeds a threshold, the structure may be converted into a balanced tree to improve lookup performance.
This optimization was introduced as part of improvements described in:
https://openjdk.org/jeps/180
However, treeification is conditional. It only occurs when the bucket size exceeds a threshold and the overall capacity is sufficiently large. This means that under certain conditions, even modern HashMap implementations can degrade to linear-time lookups.
Code Example
Map<String, Integer> aggregationMap = new HashMap<>(64);
for (int i = 0; i < 500000; i++) {
String key = "txn-" + (i % 10000);
aggregationMap.put(key, aggregationMap.getOrDefault(key, 0) + 1);
}This pattern is common in aggregation pipelines where repeated updates occur for a limited set of keys. While the code appears straightforward, the runtime behavior depends heavily on key distribution.
Internally, repeated updates to the same subset of keys concentrate activity within specific buckets. If those keys do not distribute well across the hash space, certain buckets become heavily populated. This leads to increased traversal time and uneven performance, especially under concurrent access patterns.
What Can Go Wrong
Collision Amplification
When multiple keys map to the same bucket, HashMap stores them in a chained structure. Internally, this means that lookup operations must traverse a sequence of nodes instead of performing direct access.
The underlying issue is usually a poorly implemented hashCode() method that fails to distribute values uniformly. In production systems, this results in inconsistent latency. Some requests complete quickly, while others take significantly longer due to traversal overhead within dense buckets.
Resizing and Rehashing Overhead
HashMap resizes when the number of entries exceeds a threshold derived from its capacity and load factor. The resizing logic is visible in the OpenJDK implementation:
https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/HashMap.java
During resizing, a new array is created, and all existing entries are rehashed and redistributed. This is not a simple copy operation; each entry must be recalculated and placed into a new bucket.
In production environments, this operation is expensive. If resizing occurs during peak traffic, it can lead to noticeable latency spikes because threads spend time performing rehashing instead of processing requests.
Treeification Is Not a Universal Solution
Although Java 8 introduced tree-based buckets to improve performance under heavy collisions, this optimization is not always triggered.
Treeification requires both a minimum bucket size and a minimum overall capacity. If these conditions are not met, the structure remains a linked list. As a result, systems with moderate-sized maps and poor hash distribution can still experience linear-time lookups, even on modern JVMs.
Memory Overhead and Garbage Collection
Each entry in a HashMap is represented by an object that includes additional metadata such as the hash value and a reference to the next node. As the number of entries increases, the memory footprint grows significantly.
This increased memory usage leads to higher garbage collection activity. The JVM garbage collector behavior and its impact on performance are documented here:
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/
In production systems, this manifests as longer GC pauses and reduced throughput, especially when large maps are frequently resized or updated.
Performance & Scalability
Behavior Under Real Load
In ideal conditions, HashMap provides constant-time performance. However, real-world data rarely follows ideal distributions. Skewed key patterns create hotspots where certain buckets receive a disproportionate number of entries.
Internally, this leads to uneven performance characteristics. While some operations remain efficient, others degrade due to traversal overhead. This inconsistency is a common cause of unpredictable latency in high-throughput systems.
Impact of Resizing on Throughput
Resizing is a computationally intensive operation that involves rehashing all entries. When this occurs during peak load, it reduces the system’s ability to process incoming requests.
Even a single resize operation can temporarily degrade throughput. In systems with strict latency requirements, such spikes can cascade into broader performance issues, affecting upstream and downstream services.
Garbage Collection Pressure
Large HashMaps contribute to increased heap usage and object retention. Each insertion creates new node objects, and resizing operations temporarily increase memory consumption.
This leads to more frequent garbage collection cycles and longer pause times. In latency-sensitive applications, these pauses directly impact response times and overall system stability.
Trade-offs & Design Decisions
HashMap is optimized for fast access in environments where concurrency is limited and key distribution is relatively uniform. Its design emphasizes simplicity and performance.
However, this comes at the cost of thread safety and predictability under non-ideal conditions. When used in environments with high concurrency or skewed data patterns, its performance characteristics can become unpredictable.
Choosing HashMap requires understanding these trade-offs and ensuring that the system’s data patterns align with its assumptions. In cases where they do not, alternative data structures should be considered.
When NOT to Use HashMap
HashMap is not suitable for multi-threaded environments where concurrent modifications occur without synchronization. Internally, this can lead to inconsistent state or structural corruption.
It is also not appropriate when iteration order matters, as HashMap does not guarantee ordering. Additionally, in systems where key distribution is inherently skewed, HashMap can become a performance bottleneck.
Real-World Use Case
In a rate-limiting service, HashMap was used to track request counts per user. Initially, the system performed well under moderate load. However, as traffic increased, certain users generated significantly more requests than others.
This caused specific buckets to become heavily populated. Internally, repeated updates to these buckets increased traversal time and CPU usage. The system exhibited uneven latency across requests.
The issue was resolved by redesigning the key structure to improve hash distribution and pre-sizing the map to reduce resizing frequency. This stabilized performance and reduced CPU overhead.
From Real Experience
A common misconception is that HashMap always provides constant-time performance. In practice, this depends on how well keys are distributed and how the map is sized.
In multiple production systems, the most frequent issues were not related to the data structure itself but to how it was used. Developers often overlooked the importance of initial capacity, leading to repeated resizing. In other cases, poorly designed keys caused excessive collisions.
One production incident involved a large in-memory cache where resizing operations alone caused cascading latency across dependent services. The resolution involved pre-sizing the map and improving key hashing, but identifying the issue required a deep understanding of HashMap internals.
Summary
HashMap works efficiently when keys are evenly distributed and the map is properly sized. It becomes slow when too many keys collide or when resizing happens frequently.

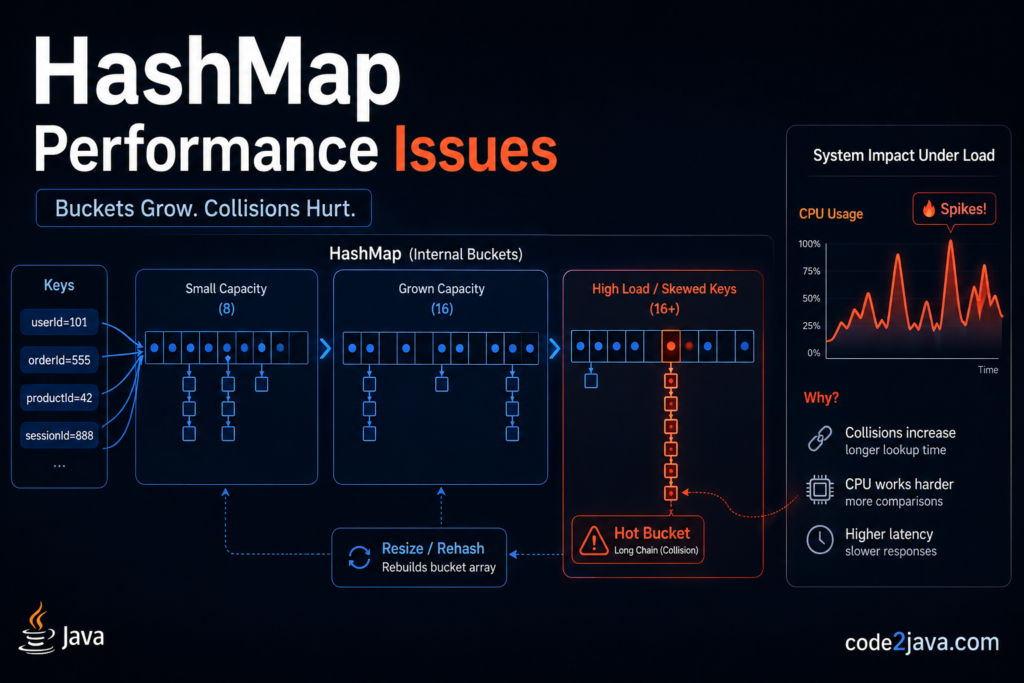
The diagram shows how a Java HashMap distributes incoming keys (based on their hash values) across an internal array of buckets. In normal conditions, hashes are well distributed, so each bucket contains only a few entries, enabling near O(1) performance for get/put operations. This “healthy” state is labeled as good hash distribution, where entries are evenly spread and stored as short linked lists.
Under production load, however, poor hash distribution or high traffic can cause multiple keys to land in the same bucket, creating collisions. These “hot buckets” grow into long chains, increasing lookup time and causing latency and CPU spikes. When a bucket becomes too large, it is converted into a red-black tree (treeification) to improve performance from linear to logarithmic time. Additionally, when the overall capacity threshold is exceeded, the HashMap triggers a resize and rehash operation, which is computationally expensive and can further impact performance.
Understanding its internal behavior helps avoid performance issues that are not immediately obvious from its API.
Advanced Scenario-Based Interview Questions
1. What happens if a system performs a large number of insertions into a HashMap?
Answer:
As the number of insertions increases, the map eventually exceeds its load factor threshold and triggers resizing. Internally, resizing involves creating a new array and rehashing all existing entries. This is computationally expensive and can cause latency spikes under heavy load. Frequent resizing can be avoided by pre-sizing the map based on expected data volume, which improves performance stability.
2. What happens if a HashMap undergoes frequent resizing?
Answer:
Frequent resizing leads to repeated rehashing of all entries, increasing CPU usage significantly. Internally, each resize operation redistributes all elements into a larger array, which is expensive. In production systems, this results in increased response times and reduced throughput. Proper capacity planning helps avoid this issue.
3. How does the system behave when multiple keys generate similar hash values?
Answer:
When hash values are not well distributed, multiple keys map to the same bucket. Internally, this forces traversal of a linked list or tree structure instead of direct access. This degrades performance from constant time to linear or logarithmic time. In production, this leads to inconsistent latency. Improving the hash function or key design restores performance.
4. What happens if a very large HashMap is used in a memory-constrained system?
Answer:
A large HashMap consumes significant heap space due to object overhead and metadata. Internally, this increases memory pressure and triggers more frequent garbage collection. This results in longer GC pauses and reduced system throughput. Limiting map size or using alternative data structures can mitigate this issue.
5. What issues arise when using HashMap in a multi-threaded environment?
Answer:
HashMap is not thread-safe, so concurrent modifications can lead to inconsistent state or structural issues. Internally, simultaneous updates can interfere with resizing and bucket operations. In production, this may result in data corruption or unpredictable behavior. Using ConcurrentHashMap provides better thread safety and performance in multi-threaded scenarios.
References
- https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/HashMap.java
- https://openjdk.org/jeps/180
- https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/