Event-Driven Architecture — How Distributed Systems Communicate at Scale
When teams first move from monoliths to microservices, communication usually starts with synchronous REST APIs. It feels natural because it closely resembles how applications behaved before the migration. One service sends a request, waits for a response, and then continues processing. Initially, this model appears simple, predictable, and easy to understand.
As systems grow, the communication layer often becomes one of the biggest sources of operational complexity. This is where event-driven architecture begins to emerge as a critical design approach for large-scale distributed systems.
1. Why Synchronous Communication Starts Breaking Down
In the early stages of microservices journey, direct service-to-service communication seems efficient. The Order Service calls the Payment Service, the Payment Service calls the Inventory Service, and the workflow progresses step by step.
The challenge appears when these chains become longer.
A simple customer transaction may eventually travel through authentication services, payment systems, inventory management, fraud detection, notification platforms, analytics pipelines, and audit systems. Every additional service introduces another network hop, another dependency, and another potential point of failure.
As traffic grows, latency starts accumulating across the request path. A small slowdown in one service forces upstream services to wait longer. Threads remain blocked, request queues grow, and retry mechanisms begin generating additional traffic. What initially looked like independent services slowly becomes a tightly coupled runtime dependency chain.
The architecture may be distributed on paper, but operationally it still behaves like one large interconnected system.
2. Event-Driven Architecture Changes the Communication Model
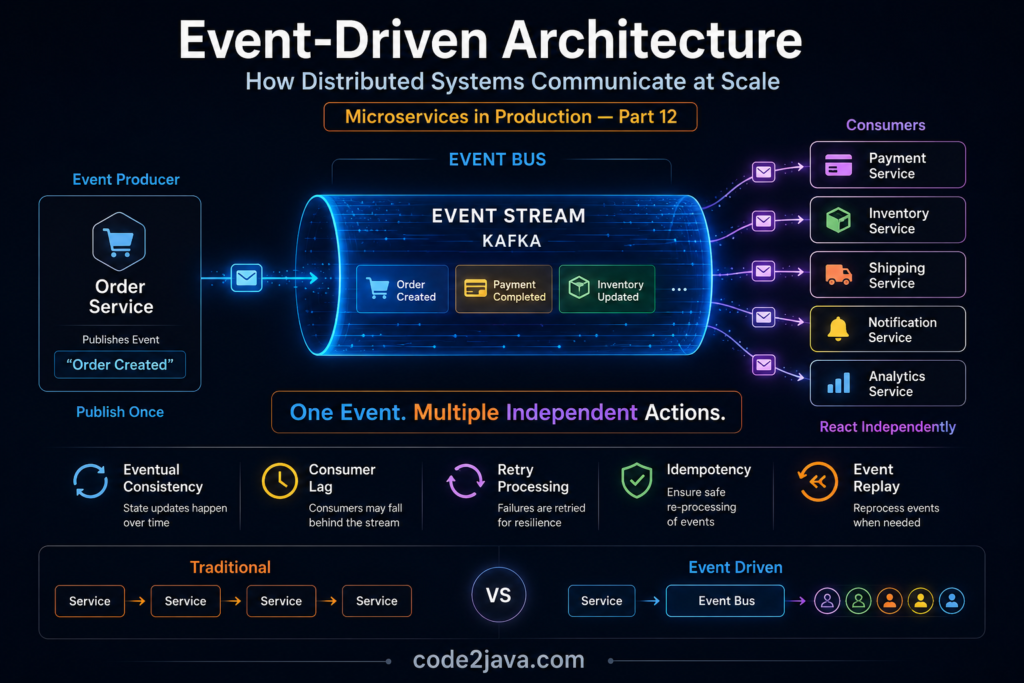
Event-driven architecture approaches communication from a completely different perspective. Instead of continuously asking other services to perform work, a service simply announces that something has happened. Other services can then react independently whenever necessary.
Consider an order placement workflow. In a traditional synchronous model, the Order Service might directly invoke Payment, Inventory, Notification, and Shipping services before completing the transaction. Every dependency must be available and responsive at that moment.
In an event-driven model, the Order Service publishes an “Order Created” event. Downstream services consume that event independently and perform their own processing. The order service does not need to wait for every operation to complete before moving forward.
This significantly reduces runtime coupling. Services become connected through business events rather than direct request dependencies. The communication model shifts from command-driven interactions to event-driven reactions.
3. Why Organizations Adopt Kafka and Event Streaming Platforms
As event-driven architectures mature, organizations need infrastructure capable of handling large volumes of events reliably. This is where platforms such as Kafka become central to the architecture.
Instead of services communicating directly with each other, they communicate through an event stream. Producers publish events into the platform, while consumers subscribe and process those events independently.
This creates several important operational advantages.
- Traffic spikes become easier to absorb because events can be buffered temporarily
- Downstream outages no longer immediately impact upstream services because messages remain available until consumers recover
- Services can also evolve independently because producers and consumers no longer require tight runtime coordination.
From a production perspective, Kafka becomes much more than a messaging platform, it becomes the communication backbone of the distributed system.
Many large-scale architectures eventually rely on event streams for everything from business workflows and analytics to auditing, monitoring, and system integration.
4. Eventual Consistency Becomes a Normal System Behavior
One of the biggest mindset shifts when adopting event-driven architecture involves consistency.
Inside a monolithic application, transactions often execute within a single database transaction. Once the transaction commits, every component sees the same state immediately.
Distributed event-driven systems behave differently. An event may be published immediately, but downstream services process that event at different times. Some consumers may complete processing within milliseconds, while others may take seconds or even minutes.
This means different services may temporarily hold different views of the same business process.
For example, an order may already appear in the order system while inventory allocation remains pending. A payment may be completed while customer notifications have not yet been delivered.
From a distributed systems perspective, this is not a failure, it is expected behaviour.
The architecture intentionally accepts temporary inconsistency in exchange for scalability, resilience, and loose coupling.
5. Why Duplicate Events Become a Reality
Many teams assume that events will always be processed exactly once. In practice, distributed systems rarely provide such guarantees. Network interruptions, consumer restarts, broker failovers, and retry mechanisms can all result in the same event being delivered multiple times.
This introduces an important challenge – Consumers must be capable of handling duplicate messages safely.
Imagine a payment event being processed twice because a consumer crashed after completing the payment but before acknowledging the message. Without proper safeguards, the system could potentially charge a customer twice.
This is why idempotency becomes one of the most important design principles in event-driven systems. A well-designed consumer should produce the same outcome regardless of how many times it receives the same event.
At scale, duplicate delivery is not an exception, It is a normal operational scenario.
6. Consumer Lag Slowly Becomes a Production Problem
One of the most overlooked aspects of event-driven systems is consumer lag. Consumer lag represents the gap between events being produced and events being processed.
When systems operate normally, consumers process messages quickly enough to keep pace with incoming traffic. During periods of increased load, however, consumers may begin falling behind.
Initially, this may not appear problematic. The application continues functioning, APIs remain available, and infrastructure appears healthy. Meanwhile, event backlogs quietly grow inside the messaging platform.
Over time, delayed processing starts affecting business workflows –
- Notifications arrive late
- Reporting systems become outdated
- Inventory synchronization drifts
- Customer-facing systems begin operating on stale information.
Consumer lag often becomes one of the earliest indicators that the distributed system is struggling under load. Unfortunately, many teams discover it only after business processes start behaving unexpectedly.
7. Event Ordering Is Harder Than Most Teams Expect
A common assumption in event-driven systems is that events will always arrive in the order they were created, reality is far more complicated.
Distributed systems process events across multiple partitions, consumers, threads, and infrastructure nodes. As workloads scale, maintaining perfect global ordering becomes extremely difficult.
An “Order Cancelled” event may arrive before an “Order Created” event reaches a particular consumer. Parallel processing may introduce race conditions between related business operations.
These situations are not necessarily bugs, they are consequences of operating distributed systems at scale.
Successful event-driven architectures acknowledge this reality and design workflows that tolerate ordering challenges rather than depending on perfect sequencing everywhere.
8. Event Choreography Creates Both Freedom and Complexity
One of the greatest strengths of event-driven systems is flexibility. Services can subscribe to events without requiring changes to existing producers. New business capabilities can often be introduced simply by consuming existing event streams.This creates tremendous agility.
However, at the same time, it introduces a new form of complexity. As the number of services grows, understanding the complete execution path of a business transaction becomes increasingly difficult. A single event may trigger dozens of downstream processes across unrelated systems.
Unlike traditional orchestration models, no single service necessarily controls the entire workflow. This phenomenon is often called event choreography. While it reduces coupling, it also makes systems harder to visualize, debug, and reason about during production incidents.
The architecture becomes operationally powerful but conceptually more difficult to understand.
9. Event-Driven Systems Move Complexity Rather Than Eliminate It
One of the most important lessons architects learn is that event-driven architecture does not remove complexity, it simply relocates it.
Synchronous systems concentrate complexity around direct service dependencies and request chains. Event-driven systems reduce those dependencies but introduce challenges around consistency, retries, ordering, monitoring, and debugging.
The architecture becomes more resilient to temporary failures, but operational visibility becomes increasingly important.
Engineers must now understand not only where requests travel but also how events propagate throughout the platform. The communication model becomes more scalable, but the runtime behavior becomes more sophisticated.
10. Why Event-Driven Architecture Powers Modern Distributed Systems
From a production perspective, event-driven architecture fundamentally changes how distributed systems absorb load, recover from failures, and scale independently.
Instead of forcing services to communicate synchronously at every step, event streams allow workloads to be processed asynchronously based on available capacity. This creates more resilient systems that handle traffic spikes and partial outages more gracefully.
However, success requires more than simply deploying Kafka or introducing message queues. Teams must design for eventual consistency, duplicate processing, consumer lag, ordering challenges, and operational observability from the beginning.
Organizations that understand these realities build highly scalable and resilient distributed systems. Organizations that ignore them often replace one form of complexity with another.
Summary
Event-driven architecture changes how distributed systems communicate by replacing direct service dependencies with asynchronous event streams.
This reduces runtime coupling, improves scalability, and increases resilience under production load. At the same time, it introduces new challenges such as eventual consistency, duplicate processing, consumer lag, event ordering, and distributed workflow visibility.
The most important realisation is that event-driven architecture is not simply a messaging pattern, it is a different way of designing systems.
As distributed platforms continue growing in scale and complexity, event-driven communication increasingly becomes the foundation that allows services to evolve, recover, and scale independently under real production conditions.