Microservices Deployment Strategy — How Modern Teams Release Software Safely at Scale
Building microservices is often perceived as the difficult part of a distributed systems journey. Teams spend months decomposing monoliths, defining service boundaries, implementing APIs, introducing Kubernetes, and establishing communication patterns between services. Once these capabilities are in place, many organizations assume the hardest work is behind them.
In reality, a new challenge is only beginning.
Distributed systems are not static. Business requirements evolve continuously, security vulnerabilities require patching, performance improvements demand implementation, and new features must reach customers quickly. As a result, every service in the platform constantly changes. The real challenge is no longer building the system. The challenge becomes changing the system safely while it remains in production.
This is where deployment evolves from an operational activity into a platform engineering discipline.
In small applications, deployment may simply involve releasing a new version and monitoring the outcome. In large microservices environments, however, hundreds of services may be changing simultaneously. Teams deploy independently, APIs evolve continuously, infrastructure changes frequently, and customer traffic never stops. Under these conditions, releasing software becomes a distributed systems problem that requires automation, observability, traffic management, and careful risk control.
Understanding how modern organizations approach deployments is essential because the ability to release software safely often determines how quickly a business can innovate.
1. Why Deployments Become Harder After Microservices
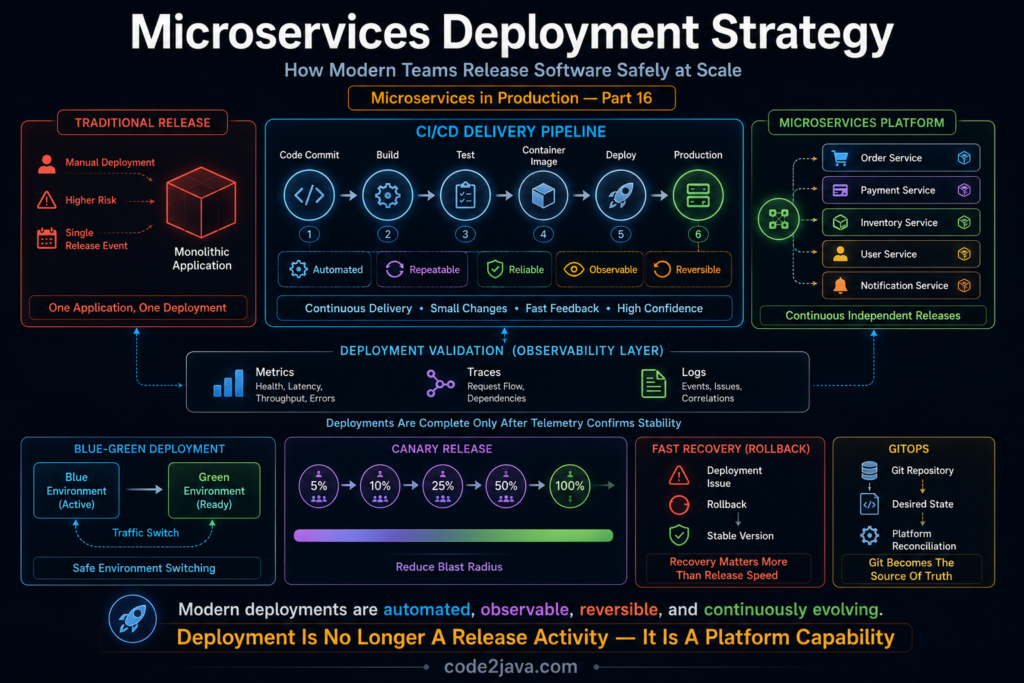
One of the major advantages of monolithic systems is operational simplicity. Regardless of how large the application becomes internally, organizations typically manage a single deployment process. Developers build one artifact, operations teams deploy one application, and rollback procedures usually involve restoring a previous version of the same system.
The deployment workflow remains relatively predictable because everything moves together.
Microservices fundamentally change this model.
Instead of deploying one application, organizations deploy dozens or even hundreds of independently evolving services. Each service may have its own release cycle, development team, testing strategy, infrastructure requirements, and dependency relationships. What was once a single deployment activity becomes a continuous stream of changes occurring across the platform.
The complexity grows rapidly because deployments no longer occur in isolation. A change in one service can affect downstream consumers, event subscribers, API clients, or dependent workflows. Even when services remain technically independent, they still participate in larger business processes that span multiple systems.
As the platform expands, deployment complexity begins growing faster than the number of services themselves. Coordinating change across a distributed environment becomes one of the most important operational challenges organizations face.
2. The Myth of Independent Deployments
One of the most widely promoted benefits of microservices is independent deployment. The idea is appealing because it allows teams to release changes without coordinating with every other team in the organization.
While this is directionally true, the reality is more nuanced. Services may deploy independently, but they rarely operate independently.
Consider an Order Service that introduces a new API contract. The development team may successfully deploy the change, but downstream consumers still need to understand and process the updated contract correctly. If the Payment Service, Notification Service, or Analytics Service expects the previous version, compatibility problems can emerge immediately.
The same challenge appears in event-driven systems. A producer may publish a new event schema while consumers continue expecting an older format. Although deployment occurred successfully from the producer’s perspective, the broader business workflow may experience failures.
This is why experienced architects focus heavily on compatibility.
Successful microservices organizations design APIs, events, and data contracts to evolve gradually. New capabilities are introduced in a backward-compatible manner, allowing services to upgrade independently without disrupting the rest of the ecosystem.
Independent deployment is therefore not about eliminating dependencies, it is about reducing deployment coordination while maintaining compatibility across the platform.
3. Why Manual Deployments Stop Scaling
Many organizations begin their software journey with manual deployment processes. Engineers build applications, execute deployment scripts, verify environments, and perform release activities themselves.
This approach works reasonably well when only a handful of applications exist. As platforms scale, however, manual deployment becomes unsustainable.
Imagine an organization operating one hundred microservices. If each service deploys only twice per week, the platform experiences approximately two hundred deployments every week. Coordinating these releases manually would consume enormous amounts of engineering time while simultaneously increasing the likelihood of mistakes.
Human-driven deployment processes introduce inconsistency. Engineers may forget steps, execute commands incorrectly, or perform releases differently across environments. Small mistakes can quickly propagate into production incidents.
Automation becomes essential because it transforms deployment from a human-dependent process into a repeatable system.
This is where CI/CD pipelines become critical. Rather than relying on individuals to perform deployment activities manually, pipelines automate building, testing, packaging, validation, and release processes. The result is greater consistency, reduced operational risk, and significantly faster delivery cycles.
As service count increases, CI/CD transitions from a productivity improvement into a fundamental operational requirement.
4. What Actually Happens During a Deployment
Many engineers interact with deployment pipelines every day without fully understanding what occurs behind the scenes.
A modern deployment involves far more than simply copying code into production. The process usually begins when a developer commits changes to a source code repository. That commit triggers an automated pipeline responsible for validating the release before it reaches customers.
A typical deployment workflow includes:
- Source code validation
- Automated unit testing
- Integration testing
- Security scanning
- Container image creation
- Artifact publication
- Environment deployment
- Health verification
- Traffic transition
- Post-deployment monitoring
Once the application successfully passes validation, deployment platforms begin replacing older application instances with newer versions. In Kubernetes environments, this often means creating new pods, performing readiness checks, gradually shifting traffic, and removing older instances only after the platform confirms that the new version is healthy.
What appears to developers as a single deployment action is actually a carefully orchestrated sequence designed to reduce risk while maintaining service availability.
Understanding this lifecycle becomes increasingly important because every stage contributes to overall deployment safety.
5. Why Rollbacks Matter More Than Deployments
Organizations often spend significant effort optimizing deployment speed.
Experienced engineering teams usually focus on something else — Recovery speed.
Every deployment introduces uncertainty. Even well-tested releases can behave differently under production traffic. Infrastructure configurations may interact unexpectedly with application code. Hidden dependencies may reveal problems only after real users begin interacting with the system.
For this reason, mature organizations assume that some deployments will eventually fail. The objective is not achieving perfect deployments, but to minimize the impact of failures when they occur.
Rollback strategies provide this safety mechanism.
A reliable rollback process allows teams to restore a known-good state quickly when deployments introduce instability. Instead of spending hours diagnosing issues while customers experience degraded service, teams can revert changes, stabilize the platform, and investigate problems afterward.
The ability to recover rapidly often contributes more to operational resilience than the ability to deploy rapidly.
In production engineering, recovery capabilities frequently matter more than deployment capabilities.
6. Blue-Green Deployments Reduce Release Risk
One of the simplest ways to reduce deployment risk is to separate new releases from live traffic until validation is complete. Blue-Green deployment strategies accomplish this by maintaining two independent environments.
The Blue environment represents the currently active production version serving customer traffic. The Green environment contains the new release awaiting validation.
Rather than replacing the active version directly, teams deploy the new version into the Green environment while Blue continues serving users normally. Engineers can verify functionality, perform health checks, execute automated tests, and evaluate operational metrics without affecting production traffic. Only after validation succeeds does traffic move from Blue to Green.
This approach significantly reduces deployment risk because organizations always maintain a fully functional fallback environment. If problems emerge after traffic shifts, teams can quickly redirect traffic back to the previous version.
The trade-off is increased infrastructure cost because two production-capable environments must exist simultaneously. For many organizations, however, the additional cost is justified by the increased deployment safety.
7. Canary Deployments Minimize Blast Radius
While Blue-Green deployments focus on environment switching, Canary deployments focus on controlled exposure. Instead of releasing a new version to all users simultaneously, organizations expose the release to a small percentage of traffic first.
A typical progression might look like:
- 5% of traffic
- 10% of traffic
- 25% of traffic
- 50% of traffic
- 100% of traffic
This strategy provides an opportunity to observe real production behavior before fully committing to the release. If latency increases, error rates spike, or resource consumption behaves unexpectedly, teams can stop the rollout immediately while only a small subset of users experiences the issue.
The key advantage of canary deployments is risk reduction.
Rather than treating deployment as a single high-risk event, organizations transform it into a controlled learning process. Engineers collect production feedback incrementally and use that information to decide whether broader rollout is appropriate.
As systems grow larger and customer impact becomes more significant, canary deployments become one of the most valuable tools in modern release engineering.
8. Why Observability Becomes Part of Deployment
Traditional deployment thinking assumes that the deployment process ends once the new version reaches production.
Modern engineering organizations view deployments differently – “A deployment is not complete when the code is released, but when the platform demonstrates stable behaviour“.
This distinction explains why observability has become deeply integrated into modern deployment strategies. After a release, teams closely monitor key indicators such as:
- Response latency
- Error rates
- Request throughput
- Resource utilization
- Dependency performance
- Business transaction success rates
These signals help engineers determine whether the new version behaves as expected under real traffic conditions.
Without observability, deployment decisions rely heavily on assumptions. Teams may believe a release succeeded simply because deployment automation completed successfully.
With observability, teams validate success using actual runtime behaviour. This connection between deployment and observability represents one of the most important shifts in modern platform engineering.
9. GitOps Changes How Organizations Manage Deployments
As deployment automation matured, organizations began looking for ways to make infrastructure management more predictable and auditable. This led to the rise of GitOps.
Traditional deployment models often involve engineers manually applying changes to environments. While automation may exist, operational state can gradually drift away from documented expectations.
GitOps introduces a different philosophy. Instead of treating running environments as the source of truth, Git repositories become the authoritative representation of desired system state. Deployment platforms continuously compare actual infrastructure against the configuration stored in Git and automatically reconcile differences.
This approach creates several benefits-
- Infrastructure changes become traceable
- Rollbacks become easier
- Configuration remains version-controlled
- Teams gain greater confidence that environments accurately reflect intended configurations
GitOps is not merely a deployment technique, it is a shift toward managing infrastructure with the same discipline applied to application code.
10. Why Deployment Becomes a Platform Capability
As organizations scale, deployment evolves far beyond the scope of individual engineering teams. Release management, rollback strategies, traffic control, observability integration, policy enforcement, security validation, and infrastructure automation all become shared concerns across the platform.
Eventually, deployment stops being an activity performed by developers, it becomes a capability provided by the platform itself.
This transition is one of the defining characteristics of mature engineering organizations. Rather than forcing every team to build deployment processes independently, platform teams provide standardized tooling, automation, and operational guardrails that allow services to deploy safely and consistently.
The result is a system where innovation can occur rapidly without sacrificing reliability.
Organizations that master this capability gain a significant competitive advantage because they can deliver changes continuously while maintaining production stability.
In modern distributed systems, deployment is no longer simply about releasing software, it is about creating a platform that enables change safely, predictably, and repeatedly at scale.
Summary
Microservices increase development flexibility, but they also transform software delivery into a complex operational challenge. As the number of services grows, deployment becomes less about releasing code and more about managing risk across a constantly evolving distributed system.
Successful organizations address this challenge through automation, compatibility management, rollback strategies, progressive delivery techniques, observability, and GitOps-based operations. These capabilities allow teams to release changes continuously while maintaining reliability and customer trust.
The most important lesson is that modern deployment strategies are not primarily about speed. They are about confidence. Organizations that can deploy safely, detect problems quickly, and recover effectively create platforms capable of evolving continuously without compromising stability.