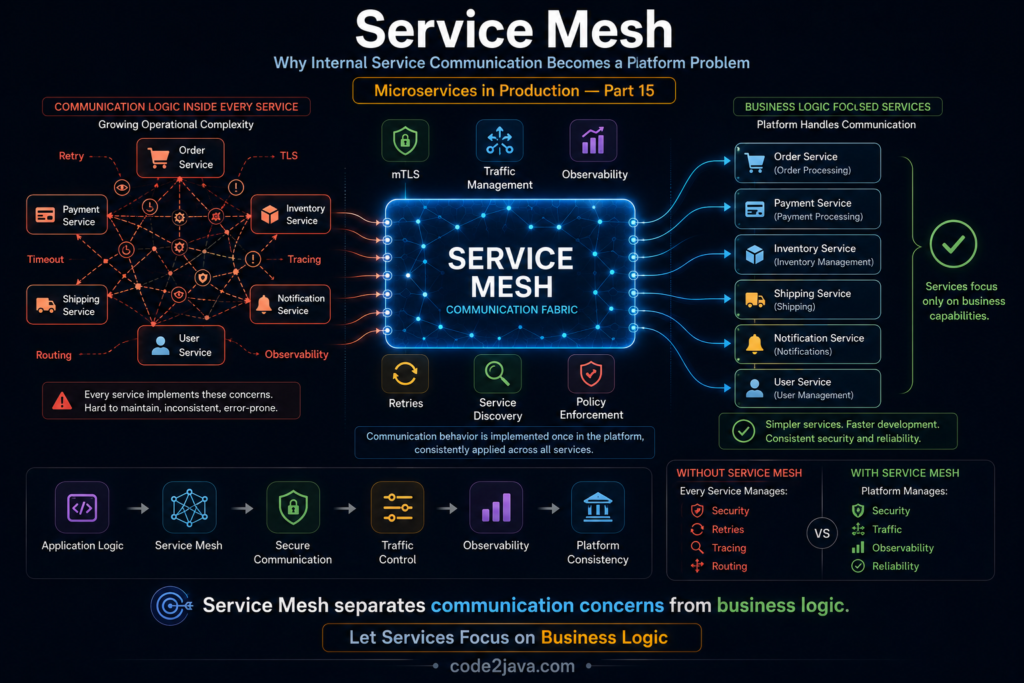
Service Mesh — Why Internal Service Communication Becomes a Platform Problem
As organizations adopt microservices, they often focus on the benefits that come from decomposing large applications into smaller, independently deployable services. Teams gain autonomy, deployments become faster, and individual services can evolve at their own pace. During the early stages of this journey, communication between services appears relatively simple. One service calls another, data flows through APIs, and the platform continues functioning as expected.
The challenge begins when the number of services starts growing.
What initially felt like a straightforward communication model gradually becomes one of the most complex aspects of operating a distributed system. Every new service introduces additional network interactions, additional security requirements, additional failure scenarios, and additional operational responsibilities. As the platform expands, organizations eventually realize that building services is not the difficult part.
Managing communication between services becomes the real challenge.
This realization is what led to the emergence of Service Mesh as one of the most important platform engineering concepts in modern distributed systems.
1. Why Service-to-Service Communication Becomes Difficult at Scale
One of the biggest misconceptions about microservices is the assumption that smaller services automatically lead to simpler systems. While individual services may become easier to understand, the platform as a whole often becomes significantly more complex because communication now happens across a network rather than within a single application process.
Inside a monolithic application, components interact through local method calls. Data moves within the same runtime, shares the same memory space, and executes within a predictable environment. Engineers rarely think about network latency, packet loss, service discovery, encryption, or retry behavior because these concerns simply do not exist inside a single process.
Microservices fundamentally change that reality.
Every interaction now travels across a network. Even a simple business workflow may involve multiple service calls before a transaction completes successfully. A customer placing an order might trigger communication between authentication services, order management systems, payment processors, inventory services, shipping platforms, and notification systems. What previously existed as a sequence of local method calls becomes a chain of distributed network operations.
As the number of services grows, the complexity of these interactions grows even faster. The platform begins accumulating thousands of communication paths, each requiring security, reliability, observability, and failure handling. At this point, communication itself becomes a platform-wide concern rather than an implementation detail hidden inside individual applications.
2. How Infrastructure Concerns Start Polluting Business Services
When organizations first encounter communication challenges, the most natural response is to solve them directly inside application code.
Teams introduce retry mechanisms to handle transient failures. They add timeout configurations to prevent requests from hanging indefinitely. Security teams require encryption, so developers implement TLS libraries. Observability initiatives lead to tracing frameworks, logging integrations, and telemetry instrumentation appearing across every service.
Initially, these additions seem harmless.
Over time, however, a different problem emerges. Every service begins carrying its own version of infrastructure logic. One team configures retries differently from another. Some services enforce aggressive timeout policies while others allow requests to wait longer. Security implementations vary across teams, and observability standards become inconsistent throughout the platform.
As a result, business services slowly become filled with code that has nothing to do with business functionality.
A payment service should primarily focus on payment processing. An inventory service should focus on inventory management. Instead, developers increasingly spend time managing communication behavior, security policies, networking concerns, and telemetry integrations.
The platform reaches a stage where solving infrastructure problems consumes almost as much effort as solving business problems.
This is often the moment organizations recognize that communication concerns should not belong inside individual services.
3. Service Mesh Separates Business Logic from Platform Logic
Service Mesh emerged as a solution to this growing operational burden by introducing a clear separation between business responsibilities and communication responsibilities.
The fundamental idea behind a Service Mesh is not to improve application functionality. Its purpose is to move common communication concerns out of application code and into a dedicated platform layer that can manage them consistently across the entire ecosystem.
This shift has profound architectural implications.
Instead of forcing every service team to implement retries, traffic policies, encryption standards, observability instrumentation, and service discovery logic independently, the platform assumes responsibility for those capabilities. Services continue focusing on business workflows while the mesh manages how communication occurs between them.
This separation creates consistency across the organization because communication behavior becomes standardized rather than implemented differently by every team. It also simplifies application development because engineers can focus on delivering business value without repeatedly solving the same networking problems.
Perhaps most importantly, it allows organizations to evolve platform capabilities independently of business services. Security policies can improve, observability standards can evolve, and traffic management strategies can change without requiring modifications to application code.
As distributed systems continue growing, this separation becomes one of the strongest arguments for adopting a Service Mesh.
4. Sidecars — The Hidden Runtime Layer Behind the Mesh
Understanding Service Mesh requires understanding one of its most important architectural concepts: the sidecar.
Although sidecars are often presented as a technical implementation detail, they are actually the mechanism that makes the entire mesh model possible.
Without a Service Mesh, applications communicate directly with one another. The application itself manages communication, networking behavior, and interaction policies. This means every service must understand how to implement and maintain these capabilities.
A Service Mesh introduces a different approach.
Instead of communicating directly, services communicate through lightweight proxies that run alongside them. These proxies, commonly known as sidecars, act as intermediaries responsible for managing network communication on behalf of the application.
When a service sends a request, the request first reaches the local sidecar. The sidecar applies security policies, routing decisions, retry logic, timeout configurations, and observability instrumentation before forwarding the request to its destination. The receiving service follows the same pattern, with its own sidecar processing the request before delivering it to the application.
From the perspective of the business service, very little changes. The application continues sending and receiving requests exactly as before.
What changes is where communication intelligence resides.
Instead of embedding communication logic inside every service, organizations centralize it within the mesh infrastructure. This allows communication behavior to evolve independently from business functionality while maintaining consistency across the platform.
5. Why mTLS Becomes Practical at Scale
Security becomes increasingly difficult as distributed systems expand.
In small environments, teams can manually configure secure communication between services. Certificates can be issued individually, trust relationships can be established manually, and certificate rotation can be managed through operational processes.
This approach works reasonably well when only a handful of services exist.
As the platform grows, however, manual security management becomes increasingly difficult to sustain. Hundreds of services may require certificates. Thousands of trust relationships must remain synchronized. Certificate expiration, rotation, and renewal become continuous operational responsibilities that demand significant attention from engineering teams.
The challenge is not understanding how TLS works, the challenge is operating TLS at scale. This is where Service Mesh provides enormous value.
Modern meshes typically implement mutual TLS, or mTLS, as a built-in capability. Rather than requiring developers to configure encryption manually, the mesh automatically establishes secure communication channels between services. Certificates are generated, distributed, rotated, and validated by the platform itself.
As a result, encrypted communication becomes the default behavior rather than an optional feature that teams must remember to implement.
This dramatically improves security posture while simultaneously reducing operational complexity. Instead of treating encryption as an application concern, organizations elevate it into a platform capability that applies consistently across every service interaction.
6. Traffic Management Evolves Beyond Simple Routing
Many engineers initially associate Service Mesh with networking, but its impact extends far beyond basic request routing.
As platforms mature, deployment safety becomes one of the most important operational concerns. Releasing software to production always introduces risk, regardless of how thoroughly teams test their applications beforehand. Production environments contain traffic patterns, user behaviors, and dependency interactions that are difficult to replicate elsewhere.
To reduce deployment risk, organizations increasingly rely on progressive delivery strategies.
Instead of immediately directing all traffic to a new version, teams gradually increase exposure while monitoring system behavior. A small percentage of users may initially receive the new release. If performance remains stable and error rates remain acceptable, additional traffic is directed toward the updated version.
Implementing these capabilities directly within applications can be complicated and difficult to maintain.
A Service Mesh transforms traffic management into a platform-level capability. Canary deployments, blue-green releases, traffic splitting, and controlled rollouts become configuration decisions rather than development projects.
This allows engineering teams to experiment, validate, and deploy software more safely while reducing the operational burden placed on individual services.
7. Observability Improves Without Requiring Changes Everywhere
One of the recurring themes throughout this series has been the importance of observability in distributed systems.
As service count increases, understanding runtime behavior becomes progressively more difficult. Engineers need visibility into latency, request paths, dependency relationships, error rates, and traffic patterns across the entire platform.
Achieving this visibility through application instrumentation alone can be challenging.
Every service must generate telemetry correctly. Every team must adopt consistent observability practices. Every deployment must maintain instrumentation standards over time. Maintaining this consistency across hundreds of services often becomes difficult.
Service Mesh simplifies this challenge by observing communication directly at the network layer.
Because every request passes through sidecars, the mesh gains visibility into service interactions automatically. Latency measurements, dependency maps, traffic statistics, and error rates become available without requiring extensive modifications to application code.
This does not eliminate the need for business-level observability. Applications still need domain-specific metrics and traces.
However, the mesh provides a powerful foundation by making service communication itself observable. This dramatically improves visibility while reducing the effort required to maintain observability standards across the platform.
8. Every Benefit Comes With Additional Complexity
Service Mesh solves many communication challenges, but it is important to understand that it does not eliminate complexity.
It redistributes complexity.
The operational burden previously spread across applications now moves into platform infrastructure. Sidecars, control planes, traffic policies, certificate management systems, and configuration layers become part of the production environment. These components require deployment, monitoring, maintenance, upgrades, and operational expertise.
As a result, the platform becomes more powerful but also more sophisticated.
Troubleshooting can become particularly challenging because engineers must now understand both application behavior and mesh behavior. A communication problem may originate from application code, routing policies, security configurations, certificate issues, or sidecar interactions.
Organizations therefore need sufficient operational maturity before adopting a mesh.
The goal is not to eliminate complexity completely.
The goal is to centralize complexity in a location where it can be managed consistently and efficiently.
9. When Does an Organization Actually Need a Service Mesh?
One of the most practical questions architects ask is whether their organization truly needs a Service Mesh.
The answer depends less on technology trends and more on operational reality.
A platform containing a small number of services often gains limited value from introducing a mesh. Teams can usually manage communication concerns directly without excessive difficulty. Adding a mesh in these situations may increase operational overhead without delivering proportional benefits.
The equation changes as service count increases.
Organizations operating large-scale distributed systems frequently encounter recurring challenges related to security, observability, traffic management, and communication consistency. At this stage, solving these concerns independently inside every service becomes inefficient.
A Service Mesh becomes valuable when communication itself has become difficult to manage.
This distinction is important because Service Mesh is not a prerequisite for microservices success. It is a platform optimization that helps organizations manage complexity once communication grows into a significant operational concern.
10. Why Service Mesh Represents the Evolution of Platform Engineering
One of the broader trends in modern software architecture is the gradual movement of shared responsibilities away from individual applications and into platform capabilities.
Authentication increasingly becomes a centralized service. API Gateways manage external traffic. Observability platforms provide unified visibility. Deployment platforms standardize release processes.
Service Mesh follows the same pattern.
Rather than requiring every engineering team to solve communication challenges independently, organizations create a shared communication layer that provides security, observability, resilience, and traffic management consistently across the ecosystem.
This approach allows teams to focus more on business functionality while relying on platform capabilities to solve common operational problems.
In many ways, Service Mesh represents the next stage of platform engineering maturity. It acknowledges that communication is no longer just an application concern. Communication has become a platform concern, and managing it effectively requires dedicated infrastructure designed specifically for that purpose.
Summary
Microservices simplify service ownership and deployment independence, but they also introduce significant communication complexity. As distributed systems grow, concerns such as security, observability, retries, traffic management, and service discovery begin appearing throughout the architecture. Managing these capabilities independently inside every service eventually becomes difficult, inconsistent, and operationally expensive.
Service Mesh addresses this challenge by separating communication responsibilities from business logic. Through sidecars, centralized policies, automatic mTLS, traffic management capabilities, and built-in observability, the mesh provides a consistent platform layer that manages how services interact with one another.
However, Service Mesh is not a universal solution. It introduces additional infrastructure and operational complexity that organizations must be prepared to manage. Its greatest value emerges when service-to-service communication itself becomes a platform-scale problem.
Ultimately, Service Mesh represents a broader evolution in distributed systems architecture. Instead of solving communication challenges repeatedly inside every application, organizations solve them once at the platform level and allow development teams to focus on the business capabilities that drive value.